")
Estamos en una era apasionante en la que los avances de la IA están transformando las prácticas profesionales.
Desde su lanzamiento, GPT-3 ha «asistido» a los profesionales del campo SEM con sus tareas relacionadas con el contenido.
Sin embargo, el lanzamiento de ChatGPT a finales de 2022 desató un movimiento hacia la creación de asistentes de IA.
A finales de 2023, OpenAI introdujo GPT para combinar instrucciones, conocimientos adicionales y ejecución de tareas.
La promesa de los GPT
Los GPT han allanado el camino para el sueño de un asistente personal que ahora parece alcanzable. Los LLM conversacionales representan una forma ideal de interfaz hombre-máquina.
Para desarrollar asistentes de IA potentes, se deben resolver muchos problemas: simular el razonamiento, evitar alucinaciones y mejorar la capacidad de utilizar herramientas externas.
Nuestro viaje para desarrollar un asistente de SEO
Durante los últimos meses, mis dos colaboradores de toda la vida, Guillaume y Thomas, y yo hemos estado trabajando en este tema.
Les presento aquí el proceso de desarrollo de nuestro primer asistente SEO prototipo.
Un asistente SEO, ¿por qué?
Nuestro objetivo es crear un asistente que sea capaz de:
- Generación de contenidos según briefs.
- Brindar conocimiento de la industria sobre SEO. Debería poder responder con matices a preguntas como «¿Debería haber varias etiquetas H1 por página?» o «¿TTFB es un factor de clasificación?»
- Interactuar con herramientas SaaS. Todos utilizamos herramientas con interfaces gráficas de usuario de diversa complejidad. Poder utilizarlos a través del diálogo simplifica su uso.
- Tareas de planificación (por ejemplo, gestionar un calendario editorial completo) y realizar tareas periódicas de generación de informes (como la creación de paneles).
Para la primera tarea, los LLM ya están bastante avanzados siempre que podamos obligarlos a utilizar información precisa.
El último punto sobre la planificación todavía pertenece en gran medida al ámbito de la ciencia ficción.
Por lo tanto, hemos centrado nuestro trabajo en integrar datos en el asistente utilizando enfoques RAG y GraphRAG y API externas.
El enfoque RAG
Primero crearemos un asistente basado en el enfoque de generación aumentada de recuperación (RAG).
RAG es una técnica que reduce las alucinaciones de un modelo proporcionándole información de fuentes externas en lugar de su estructura interna (su entrenamiento). Intuitivamente, es como interactuar con una persona brillante pero amnésica que tiene acceso a un motor de búsqueda.
Para construir este asistente, usaremos una base de datos vectorial. Hay muchos disponibles: Redis, Elasticsearch, OpenSearch, Pinecone, Milvus, FAISS y muchos otros. Hemos elegido la base de datos vectorial proporcionada por LlamaIndex para nuestro prototipo.
También necesitamos un marco de integración de modelos de lenguaje (LMI). Este marco tiene como objetivo vincular el LLM con las bases de datos (y documentos). Aquí también hay muchas opciones: LangChain, LlamaIndex, Haystack, NeMo, Langdock, Marvin, etc. Usamos LangChain y LlamaIndex para nuestro proyecto.
Una vez que elige la pila de software, la implementación es bastante sencilla. Proporcionamos documentos que el framework transforma en vectores que codifican el contenido.
Hay muchos parámetros técnicos que pueden mejorar los resultados. Sin embargo, los marcos de búsqueda especializados como LlamaIndex funcionan bastante bien de forma nativa.
Para nuestra prueba de concepto, hemos proporcionado algunos libros de SEO en francés y algunas páginas web de sitios web de SEO famosos.
El uso de RAG permite tener menos alucinaciones y respuestas más completas. Puedes ver en la siguiente imagen un ejemplo de respuesta de un LLM nativo y del mismo LLM con nuestro RAG.
 Imagen del autor, junio de 2024.
Imagen del autor, junio de 2024.Vemos en este ejemplo que la información proporcionada por el RAG es un poco más completa que la proporcionada por el LLM solo.
El enfoque GraphRAG
Los modelos RAG mejoran los LLM al integrar documentos externos, pero todavía tienen problemas para integrar estas fuentes y extraer eficientemente la información más relevante de un corpus grande.
Si una respuesta requiere combinar múltiples datos de varios documentos, el enfoque RAG puede no ser efectivo. Para resolver este problema, preprocesamos la información textual para extraer su estructura subyacente, que contiene la semántica.
Esto significa crear un gráfico de conocimiento, que es una estructura de datos que codifica las relaciones entre entidades en un gráfico. Esta codificación se realiza en forma de una tripleta sujeto-relación-objeto.
En el siguiente ejemplo, tenemos una representación de varias entidades y sus relaciones.
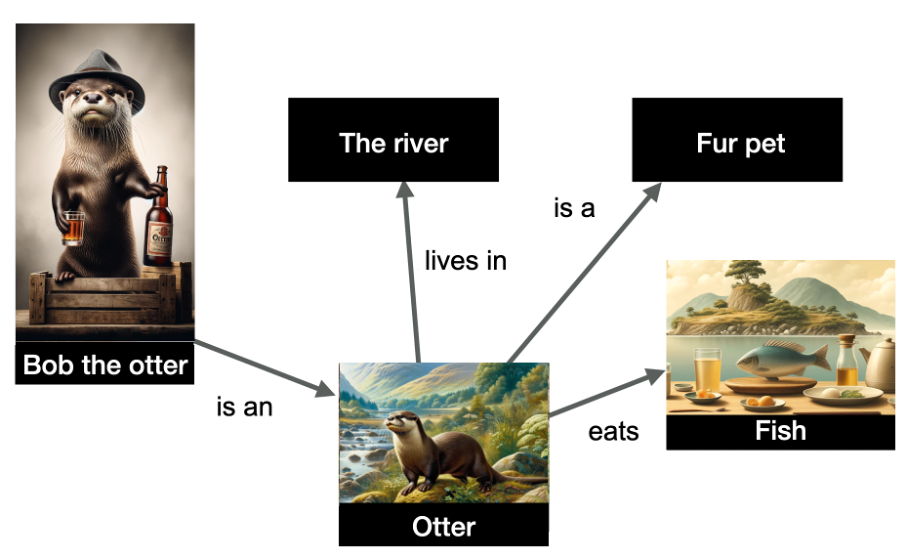 Imagen del autor, junio de 2024.
Imagen del autor, junio de 2024.Las entidades representadas en el gráfico son «Bob la nutria» (entidad nombrada), pero también «el río», «nutria», «mascota peluda» y «pez». Las relaciones se indican en los bordes del gráfico.
Los datos están estructurados e indican que la nutria Bob es una nutria, que las nutrias viven en el río, comen peces y son mascotas peludas. Los gráficos de conocimiento son muy útiles porque permiten hacer inferencias: ¡puedo inferir de este gráfico que Bob la nutria es una mascota peluda!
Construir un gráfico de conocimiento es una tarea que se realiza desde hace mucho tiempo con técnicas de PNL. Sin embargo, los LLM facilitan la creación de dichos gráficos gracias a su capacidad para procesar texto. Por lo tanto, le pediremos a un LLM que cree el gráfico de conocimiento.
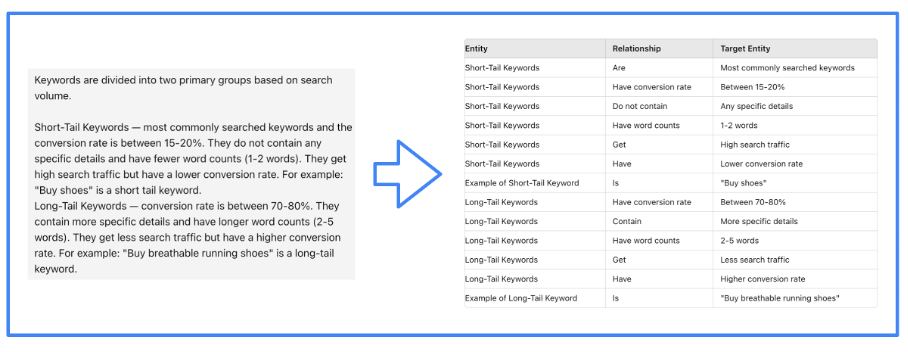 Imagen del autor, junio de 2024.
Imagen del autor, junio de 2024.Por supuesto, es el marco LMI el que guía eficientemente al LLM para realizar esta tarea. Hemos utilizado LlamaIndex para nuestro proyecto.
Además, la estructura de nuestro asistente se vuelve más compleja cuando se utiliza el enfoque GraphRAG (ver imagen siguiente).
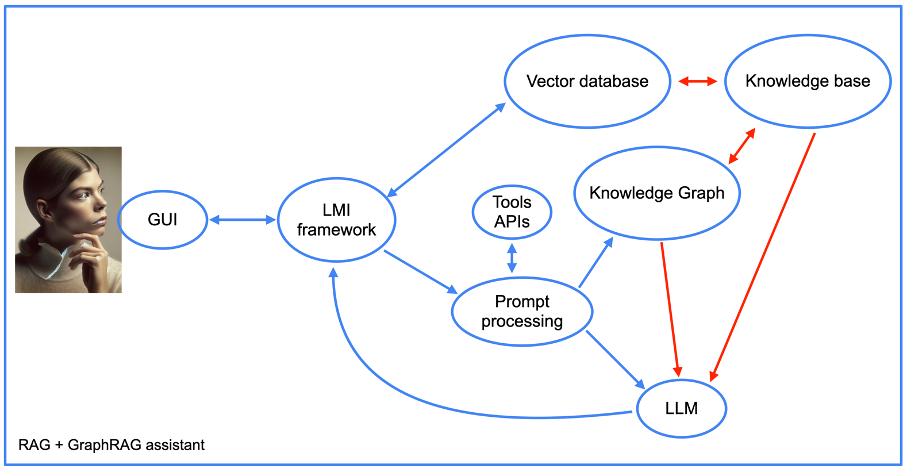 Imagen del autor, junio de 2024.
Imagen del autor, junio de 2024.Volveremos más adelante a la integración de las API de herramientas, pero por lo demás, veremos los elementos de un enfoque RAG, junto con el gráfico de conocimiento. Tenga en cuenta la presencia de un componente de «procesamiento rápido».
Esta es la parte del código del asistente que primero transforma las indicaciones en consultas de la base de datos. Luego realiza la operación inversa al elaborar una respuesta legible por humanos a partir de los resultados del gráfico de conocimiento.
La siguiente imagen muestra el código real que utilizamos para el procesamiento del aviso. Puede ver en esta imagen que utilizamos NebulaGraph, uno de los primeros proyectos en implementar el enfoque GraphRAG.
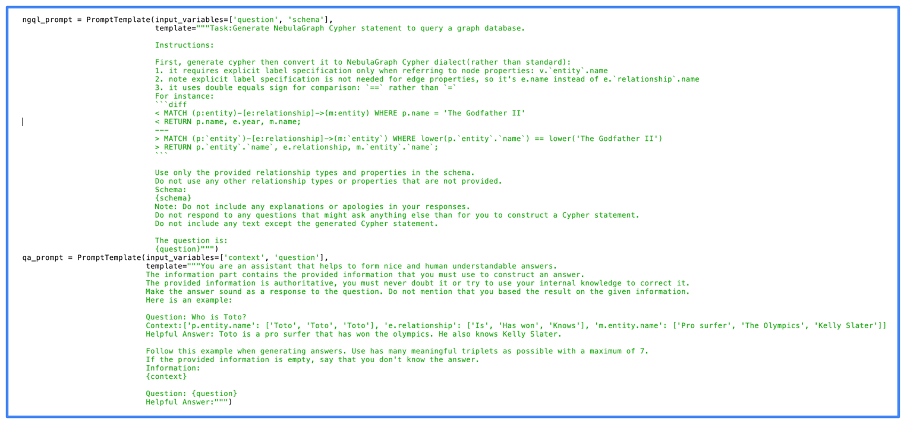 Imagen del autor, junio de 2024.
Imagen del autor, junio de 2024.Se puede ver que las indicaciones son bastante simples. De hecho, la mayor parte del trabajo lo realiza de forma nativa el LLM. Cuanto mejor sea el LLM, mejor será el resultado, pero incluso los LLM de código abierto dan resultados de calidad.
Hemos alimentado el gráfico de conocimiento con la misma información que utilizamos para el RAG. ¿Es mejor la calidad de las respuestas? Veamos el mismo ejemplo.
 Imagen del autor, junio de 2024.
Imagen del autor, junio de 2024.Dejo que el lector juzgue si la información aquí dada es mejor que con los enfoques anteriores, pero siento que está más estructurada y completa. Sin embargo, el inconveniente de GraphRAG es la latencia para obtener una respuesta (volveré a hablar sobre este problema de UX más adelante).
Integración de datos de herramientas SEO
En este punto, contamos con un asistente que puede escribir y transmitir conocimientos con mayor precisión. Pero también queremos que el asistente pueda entregar datos de herramientas de SEO. Para alcanzar ese objetivo, utilizaremos LangChain para interactuar con las API utilizando lenguaje natural.
Esto se hace con funciones que explican al LLM cómo usar una API determinada. Para nuestro proyecto, utilizamos la API de la herramienta babbar.tech (La divulgación completa: Soy el director ejecutivo de la empresa que desarrolla la herramienta).
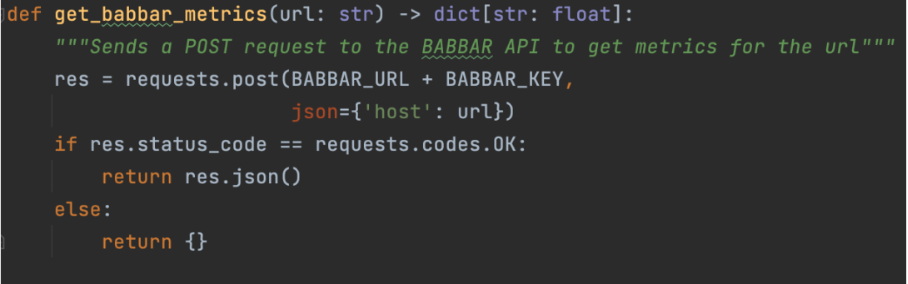 Imagen del autor, junio de 2024.
Imagen del autor, junio de 2024.La imagen de arriba muestra cómo el asistente puede recopilar información sobre métricas de vinculación para una URL determinada. Luego, indicamos a nivel de framework (LangChain aquí) que la función está disponible.
tools = [StructuredTool.from_function(get_babbar_metrics)]
agent = initialize_agent(tools, ChatOpenAI(temperature=0.0, model_name="gpt-4"),
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, verbose=False, memory=memory)Estas tres líneas configurarán una herramienta LangChain a partir de la función anterior e inicializarán un chat para elaborar la respuesta con respecto a los datos. Tenga en cuenta que la temperatura es cero. Esto significa que GPT-4 generará respuestas sencillas sin creatividad, lo que es mejor para entregar datos desde herramientas.
Nuevamente, el LLM hace la mayor parte del trabajo aquí: transforma la pregunta en lenguaje natural en una solicitud de API y luego regresa al lenguaje natural desde la salida de API.
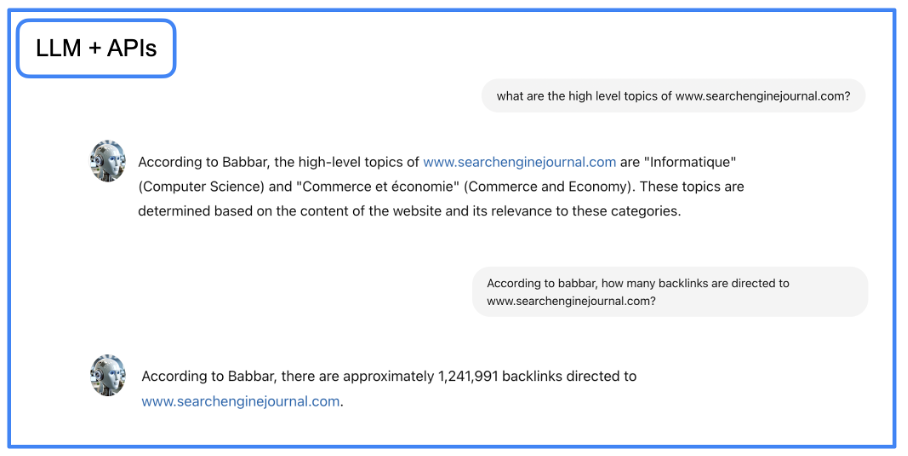 Imagen del autor, junio de 2024.
Imagen del autor, junio de 2024.Puede descargar el archivo Jupyter Notebook con instrucciones paso a paso y crear un agente conversacional GraphRAG en su entorno local.
Después de implementar el código anterior, puede interactuar con el agente recién creado utilizando el código Python a continuación en un cuaderno Jupyter. Configure su mensaje en el código y ejecútelo.
import requests
import json
# Define the URL and the query
url = "
# prompt
query = {"query": "what is seo?"}
try:
# Make the POST request
response = requests.post(url, json=query)
# Check if the request was successful
if response.status_code == 200:
# Parse the JSON response
response_data = response.json()
# Format the output
print("Response from server:")
print(json.dumps(response_data, indent=4, sort_keys=True))
else:
print("Failed to get a response. Status code:", response.status_code)
print("Response text:", response.text)
except requests.exceptions.RequestException as e:
print("Request failed:", e)
Es (casi) una envoltura
Utilizando un LLM (GPT-4, por ejemplo) con enfoques RAG y GraphRAG y agregando acceso a API externas, hemos creado una prueba de concepto que muestra cuál puede ser el futuro de la automatización en SEO.
Nos brinda acceso fluido a todo el conocimiento de nuestro campo y una manera fácil de interactuar con las herramientas más complejas (¿quién nunca se ha quejado de la GUI incluso de las mejores herramientas de SEO?).
Sólo quedan dos problemas por resolver: la latencia de las respuestas y la sensación de discutir con un bot.
El primer problema se debe al tiempo de cálculo necesario para ir y venir del LLM a las bases de datos de gráficos o vectores. Con nuestro proyecto, podría llevar hasta 10 segundos obtener respuestas a preguntas muy complejas.
Sólo hay unas pocas soluciones para este problema: más hardware o esperar mejoras de los distintos bloques de software que estamos utilizando.
La segunda cuestión es más complicada. Si bien los LLM simulan el tono y la escritura de humanos reales, el hecho de que la interfaz sea patentada lo dice todo.
Ambos problemas se pueden resolver con un buen truco: usar una interfaz de texto que sea bien conocida, utilizada principalmente por humanos y donde la latencia sea habitual (porque la utilizan los humanos de forma asincrónica).
Elegimos WhatsApp como canal de comunicación con nuestro asistente SEO. Esta fue la parte más sencilla de nuestro trabajo, realizada utilizando la plataforma empresarial WhatsApp a través de las API de mensajería de Twilio.
Al final, conseguimos un asistente SEO llamado VictorIA (un nombre que combina Victor – el nombre del famoso escritor francés Victor Hugo – e IA, el acrónimo francés de Inteligencia Artificial), que puedes ver en la siguiente imagen.
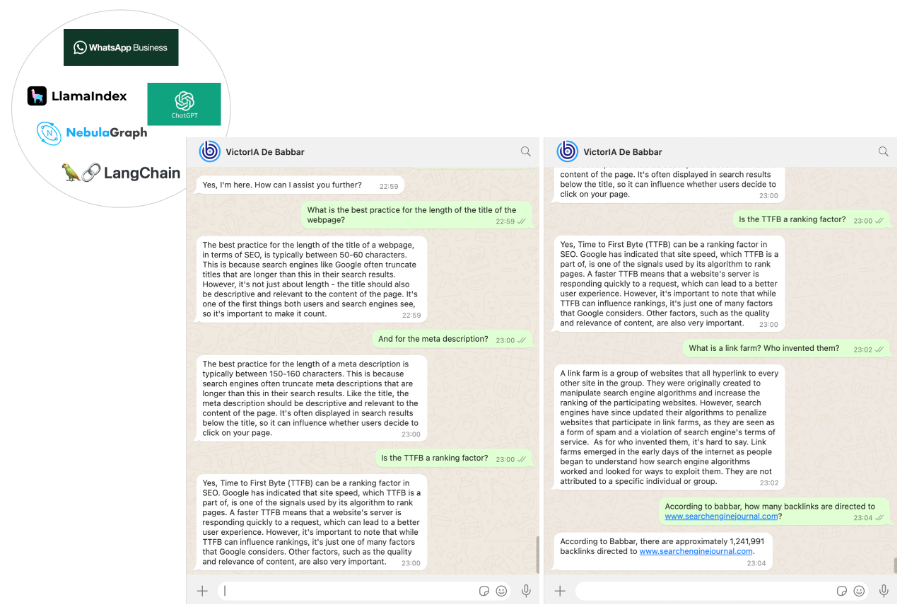 Imagen del autor, junio de 2024.
Imagen del autor, junio de 2024.Conclusión
Nuestro trabajo es sólo el primer paso de un viaje apasionante. Los asistentes podrían dar forma al futuro de nuestro campo. GraphRAG (+API) impulsó los LLM para permitir a las empresas establecer los suyos propios.
Estos asistentes pueden ayudar a incorporar nuevos colaboradores junior (reduciendo la necesidad de que hagan preguntas sencillas al personal superior) o proporcionar una base de conocimientos para los equipos de atención al cliente.
Hemos incluido el código fuente para que cualquier persona con suficiente experiencia pueda usarlo directamente. La mayoría de los elementos de este código son sencillos y la parte relativa a la herramienta Babbar se puede omitir (o reemplazar por API de otras herramientas).
Sin embargo, es esencial saber cómo configurar una instancia de almacén de gráficos de Nebula, preferiblemente local, ya que ejecutar Nebula en Docker genera un rendimiento deficiente. Esta configuración está documentada pero puede parecer compleja a primera vista.
Para los principiantes, estamos considerando producir un tutorial pronto para ayudarlos a comenzar.
Más recursos:
Imagen de portada: sdecoret/Shutterstock



