
Como especialistas en marketing, nos encantan los grandes embudos. Proporciona claridad sobre cómo están funcionando nuestras estrategias. Tenemos tasas de conversión y podemos realizar un seguimiento del recorrido del cliente desde el descubrimiento hasta la conversión. Pero en el mundo actual en el que la IA es lo primero, nuestro embudo se ha vuelto oscuro.
todavía no podemos completamente medir la visibilidad en experiencias de IA como ChatGPT o Perplexity. Si bien las herramientas emergentes ofrecen información parcial, sus datos no son completos ni consistentemente confiables. Las métricas tradicionales, como las impresiones y los clics, todavía no cuentan toda la historia en estos espacios, lo que deja a los especialistas en marketing frente a un nuevo tipo de brecha de medición.
Para ayudar a aportar claridad, veamos lo que sabemos y lo que no sabemos sobre la medición del valor de los datos estructurados (también conocido como marcado de esquema). Al comprender ambos lados, podemos centrarnos en lo que es medible y controlable hoy en día, y dónde se encuentran las oportunidades a medida que la IA cambia la forma en que los clientes descubren e interactúan con nuestras marcas.
Por qué la mayoría de los datos de ‘visibilidad de la IA’ no son reales
La IA ha creado un hambre de métricas. Los especialistas en marketing, desesperados por cuantificar lo que sucede en la parte superior del embudo, están recurriendo a una ola de nuevas herramientas. Muchas de estas plataformas están creando mediciones novedosas, como la “autoridad de marca en plataformas de IA”, que no se basan en datos representativos.
Por ejemplo, algunas herramientas intentan medir las “indicaciones de IA” tratando frases cortas de palabras clave como si fueran equivalentes a las consultas de los consumidores en ChatGPT o Perplexity. Pero este enfoque es engañoso. Los consumidores están escribiendo mensajes más largos y ricos en contexto que van mucho más allá de lo que sugieren las métricas basadas en palabras clave. Estas indicaciones son matizadas, conversacionales y altamente personalizadas, nada que ver con las consultas tradicionales de cola larga.
Estas métricas sintéticas ofrecen un falso confort. Distraen la atención de lo que es realmente medible y controlable. El hecho es que ChatGPT, Perplexity e incluso las descripciones generales de IA de Google no nos brindan datos de visibilidad claros y completos.
Entonces, ¿qué podemos medir que realmente afecte la visibilidad? Datos estructurados.
¿Qué es la visibilidad de búsqueda de IA?
Antes de profundizar en las métricas, vale la pena definir la «visibilidad de búsqueda de IA». En el SEO tradicional, la visibilidad significaba aparecer en la página uno de los resultados de búsqueda o ganar clics. En un mundo impulsado por la IA, la visibilidad significa ser comprendido, confiable y referenciado tanto por los motores de búsqueda como por los sistemas de IA. Los datos estructurados juegan un papel en esta evolución. Ayuda a definir, conectar y aclarar las entidades digitales de su marca para que los motores de búsqueda y los sistemas de inteligencia artificial puedan comprenderlas.
Lo conocido: lo que podemos medir con confianza para datos estructurados
Hablemos de lo que se conoce y se puede medir hoy en día con respecto a los datos estructurados.
Aumento de las tasas de clics a partir de resultados enriquecidos
A partir de los datos de nuestra revisión comercial trimestral, vemos que, al implementar datos estructurados en una página, el contenido califica para obtener un resultado enriquecido y las marcas empresariales ven constantemente un aumento en las tasas de clics. Actualmente, Google admite más de 30 tipos de resultados enriquecidos, que siguen apareciendo en la búsqueda orgánica.
Por ejemplo, según nuestros datos internos, en el tercer trimestre de 2025, una marca empresarial de la industria de electrodomésticos experimentó un aumento del 300 % en las tasas de clics en las páginas de productos cuando se le otorgó un resultado enriquecido. Los resultados enriquecidos continúan brindando visibilidad y ganancias de conversión a partir de la búsqueda orgánica.
Aumento de clics sin marca gracias a una sólida vinculación de entidades
Es importante distinguir entre el marcado de esquema básico y el marcado de esquema sólido con vinculación de entidades que da como resultado un gráfico de conocimiento. El marcado de esquema describe lo que hay en una página. La vinculación de entidades conecta esas cosas con otras entidades bien definidas en su sitio y en la web, creando relaciones que definen el significado y el contexto.
Una entidad es una cosa o concepto único y distinguible, como una persona, producto o servicio. La vinculación de entidades define cómo esas entidades se relacionan entre sí, ya sea a través de fuentes autorizadas externas como Wikidata y el gráfico de conocimiento de Google o su propio gráfico de conocimiento de contenido interno.
Por ejemplo, imagine una página sobre un médico. El marcado del esquema describiría al médico. Robusto, semántico El marcado también se conectaría con Wikidata y el gráfico de conocimiento de Google para definir su especialidad, al mismo tiempo que se vincularía con el hospital y los servicios médicos que brindan.
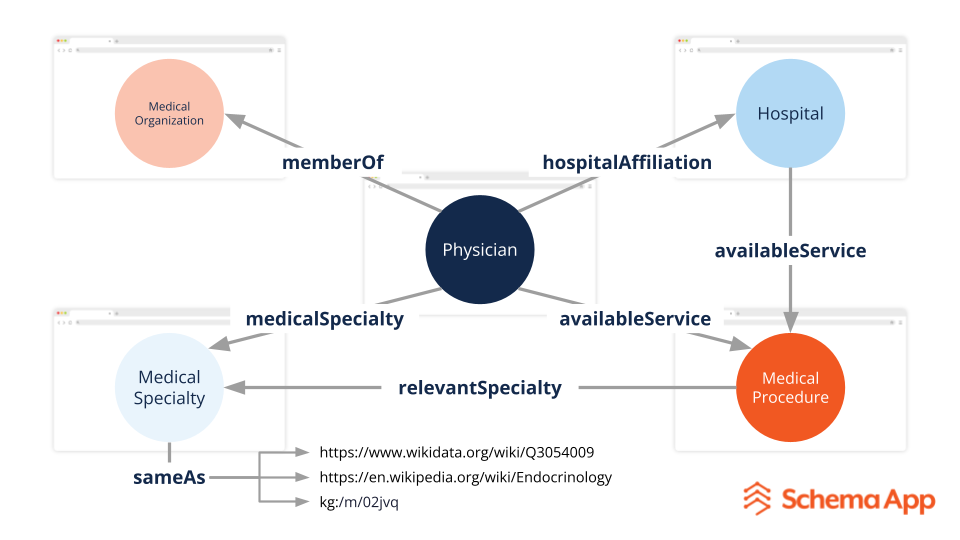 Imagen del autor, noviembre de 2025.
Imagen del autor, noviembre de 2025.Visibilidad todo en uno
Las métricas de SEO tradicionales aún no pueden medir las experiencias de IA directamente, pero algunas plataformas pueden identificar algunos casos en los que se menciona una marca en un resultado de descripción general de IA (AIO).
La investigación de un informe de BrightEdge encontró que la adopción de prácticas de SEO basadas en entidades respalda una mayor visibilidad de la IA. El informe señaló:
«La IA prioriza el contenido de entidades conocidas y confiables. Deje de optimizar para palabras clave fragmentadas y comience a desarrollar una autoridad temática integral. Nuestros datos muestran que el contenido autorizado tiene tres veces más probabilidades de ser citado en las respuestas de IA que las páginas con un enfoque limitado».
Lo desconocido: lo que aún no podemos medir
Si bien podemos medir el impacto de las entidades en el marcado del esquema a través de métricas de SEO existentes, todavía no tenemos visibilidad directa de cómo estos elementos influyen en el rendimiento del modelo de lenguaje grande (LLM).
Cómo los LLM utilizan el marcado de esquemas
La visibilidad comienza con la comprensión, y la comprensión comienza con los datos estructurados.
La evidencia de esto es cada vez mayor. En la publicación del blog de Microsoft del 8 de octubre de 2025, «Optimización de su contenido para su inclusión en respuestas de búsqueda de IA (publicidad de Microsoft»), Krishna Madhaven, director principal de productos de Microsoft Bing, escribió:
«Para los especialistas en marketing, el desafío es asegurarse de que su contenido sea fácil de entender y esté estructurado de una manera que los sistemas de inteligencia artificial puedan utilizar».
Añadió:
«El esquema es un tipo de código que ayuda a los motores de búsqueda y a los sistemas de inteligencia artificial a comprender su contenido».
De manera similar, el artículo de Google, «Principales formas de garantizar que su contenido funcione bien en las experiencias de inteligencia artificial de Google en la Búsqueda», refuerza que «los datos estructurados son útiles para compartir información sobre su contenido de manera legible por máquina».
¿Por qué tanto Google como Microsoft hacen hincapié en los datos estructurados? Una razón puede ser el costo y la eficiencia. Los datos estructurados ayudan a crear gráficos de conocimiento, que sirven como base para una IA más precisa, explicable y confiable. Las investigaciones han demostrado que los gráficos de conocimiento pueden reducir las alucinaciones y mejorar el rendimiento en los LLM:
Si bien el marcado de esquema en sí generalmente no se ingiere directamente para capacitar a los LLM, la fase de recuperación en los sistemas de generación aumentada de recuperación (RAG) desempeña un papel crucial en la forma en que los LLM responden a las consultas. En un trabajo reciente, el sistema GraphRAG de Microsoft genera un gráfico de conocimiento (mediante extracción de entidades y relaciones) a partir de datos textuales y aprovecha ese gráfico en su proceso de recuperación. En sus experimentos, GraphRAG a menudo supera a un enfoque RAG básico, especialmente para tareas que requieren razonamiento de múltiples saltos o conexión a tierra entre entidades dispares.
Esto ayuda a explicar por qué empresas como Google y Microsoft están alentando a las marcas empresariales a invertir en datos estructurados: es el tejido conectivo que ayuda a los sistemas de inteligencia artificial a recuperar información contextual precisa.
Más allá del SEO a nivel de página: creación de gráficos de conocimiento
Existe una distinción importante entre optimizar una sola página para SEO y crear un gráfico de conocimiento que conecte todo el contenido de su empresa. En una entrevista reciente con Robby Stein, vicepresidente de Producto de Google, se señaló que las consultas de IA pueden implicar docenas de subconsultas detrás de escena (lo que se conoce como consulta en abanico). Esto sugiere un nivel de complejidad que exige un enfoque más holístico.
Para tener éxito en este entorno, las marcas deben ir más allá de la optimización de páginas y, en su lugar, crear gráficos de conocimiento o, mejor dicho, una capa de datos que represente el contexto completo de su negocio.
La visión de la Web Semántica, realizada
Lo realmente emocionante es que la visión de la web semántica ya está aquí. Como escribieron Tim Berners-Lee, Ora Lassila y James Hendler en “The Semantic Web” (Scientific American, 2001):
«La Web Semántica permitirá que las máquinas comprendan documentos y datos semánticos, y permitirá que los agentes de software que deambulan de una página a otra ejecuten tareas sofisticadas para los usuarios».
Estamos viendo cómo esto se desarrolla hoy, con transacciones y consultas que se realizan directamente dentro de sistemas de inteligencia artificial como ChatGPT. Microsoft ya se está preparando para la siguiente etapa, a menudo llamada «web agente». En noviembre de 2024, RV Guha –creador de Schema.org y ahora en Microsoft– anunció un proyecto abierto llamado NLWeb. El objetivo de NLWeb es ser «la forma más rápida y sencilla de convertir eficazmente su sitio web en una aplicación de IA, permitiendo a los usuarios consultar el contenido del sitio utilizando directamente el lenguaje natural, como con un asistente de IA o Copilot».
En una conversación reciente que tuve con Guha, él compartió que la visión de NLWeb es ser el punto final para que los agentes interactúen con los sitios web. NLWeb utilizará datos estructurados para hacer esto:
«NLWeb aprovecha formatos semiestructurados como Schema.org… para crear interfaces de lenguaje natural utilizables tanto por humanos como por agentes de IA».
Convertir el embudo oscuro en uno inteligente
Así como carecemos de métricas reales para medir el desempeño de la marca en ChatGPT y Perplexity, tampoco tenemos todavía métricas completas para el papel del marcado de esquema en la visibilidad de la IA. Pero sí tenemos señales claras y consistentes de Google y Microsoft de que sus experiencias de IA utilizan, en parte, datos estructurados para comprender el contenido.
El futuro del marketing pertenece a las marcas que las máquinas entienden y confían en ellas. Los datos estructurados son un factor para que esto suceda.
Más recursos:
Imagen de portada: Roman Samborskyi/Shutterstock



