
Esta nueva serie de artículos se centra en trabajar con LLM para escalar sus tareas de SEO. Esperamos ayudarlo a integrar la IA en el SEO para que pueda mejorar sus habilidades.
Esperamos que haya disfrutado del artículo anterior y comprenda qué son los vectores, la distancia vectorial y las incrustaciones de texto.
Después de esto, es hora de ejercitar sus “músculos del conocimiento de la IA” aprendiendo a utilizar incrustaciones de texto para encontrar la canibalización de palabras clave.
Comenzaremos con las incrustaciones de texto de OpenAI y las compararemos.
| Modelo | Dimensionalidad | Precios | Notas |
|---|---|---|---|
| incrustación-de-texto-ada-002 | 1536 | $0,10 por 1 millón de tokens | Ideal para la mayoría de los casos de uso. |
| incrustación-de-texto-3-pequeño | 1536 | $0,002 por 1 millón de tokens | Más rápido y más barato pero menos preciso |
| incrustación-de-texto-3-grande | 3072 | $0,13 por 1 millón de tokens | Más preciso para tareas complejas relacionadas con textos largos, más lento |
(*las fichas pueden considerarse palabras).
Pero antes de comenzar, debes instalar Python y Jupyter en tu computadora.
Jupyter es una herramienta basada en web para profesionales e investigadores. Le permite realizar análisis de datos complejos y desarrollo de modelos de aprendizaje automático utilizando cualquier lenguaje de programación.
No te preocupes, es realmente fácil y lleva poco tiempo finalizar las instalaciones. Y recuerda, ChatGPT es tu amigo cuando se trata de programación.
En una palabra:
- Descargue e instale Python.
- Abra su línea de comando o terminal de Windows en Mac.
- Escribe estos comandos
pip install jupyterlabypip install notebook - Ejecute Júpiter con este comando:
jupyter lab
Usaremos Jupyter para experimentar con incrustaciones de texto; ¡Verás lo divertido que es trabajar con ellos!
Pero antes de comenzar, debe registrarse en la API de OpenAI y configurar la facturación completando su saldo.
Una vez que haya hecho eso, configure notificaciones por correo electrónico para informarle cuando su gasto exceda una cierta cantidad en Límites de uso.
Luego, obtenga las claves API en Panel > claves API, que debes mantener en privado y nunca compartir públicamente.
 Claves API de OpenAI
Claves API de OpenAIAhora tienes todas las herramientas necesarias para empezar a jugar con las incrustaciones.
- Abra la terminal de comando de su computadora y escriba
jupyter lab. - Deberías ver algo como la siguiente imagen emergente en tu navegador.
- Haga clic en Pitón 3 bajo Computadora portátil.
 laboratorio jupyter
laboratorio jupyterEn la ventana abierta, escribirás tu código.
Como pequeña tarea, agrupemos URL similares desde un CSV. El CSV de muestra tiene dos columnas: URL y Título. La tarea de nuestro script será agrupar URL con significados semánticos similares según el título para que podamos consolidar esas páginas en una y solucionar los problemas de canibalización de palabras clave.
Estos son los pasos que debe seguir:
Instale las bibliotecas de Python requeridas con los siguientes comandos en la terminal de su PC (o en la computadora portátil Jupyter)
pip install pandas openai scikit-learn numpy unidecode
Se requiere la biblioteca ‘openai’ para interactuar con la API de OpenAI para obtener incrustaciones, y ‘pandas’ se usa para la manipulación de datos y el manejo de operaciones de archivos CSV.
La biblioteca ‘scikit-learn’ es necesaria para calcular la similitud de cosenos, y ‘numpy’ es esencial para operaciones numéricas y manejo de matrices. Por último, unidecode se utiliza para limpiar texto.
Luego, descargue la hoja de muestra como CSV, cambie el nombre del archivo a páginas.csv y cárguelo en su carpeta Jupyter donde se encuentra su script.
Configure su clave API de OpenAI con la clave que obtuvo en el paso anterior y copie y pegue el código a continuación en el cuaderno.
Ejecute el código haciendo clic en el ícono del triángulo de reproducción en la parte superior del cuaderno.
import pandas as pd
import openai
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import csv
from unidecode import unidecode
# Function to clean text
def clean_text(text: str) -> str:
# First, replace known problematic characters with their correct equivalents
replacements = {
'–': '–', # en dash
'’': '’', # right single quotation mark
'“': '“', # left double quotation mark
'â€': '”', # right double quotation mark
'‘': '‘', # left single quotation mark
'â€': '—' # em dash
}
for old, new in replacements.items():
text = text.replace(old, new)
# Then, use unidecode to transliterate any remaining problematic Unicode characters
text = unidecode(text)
return text
# Load the CSV file with UTF-8 encoding from root folder of Jupiter project folder
df = pd.read_csv('pages.csv', encoding='utf-8')
# Clean the 'Title' column to remove unwanted symbols
df['Title'] = df['Title'].apply(clean_text)
# Set your OpenAI API key
openai.api_key = 'your-api-key-goes-here'
# Function to get embeddings
def get_embedding(text):
response = openai.Embedding.create(input=[text], engine="text-embedding-ada-002")
return response['data'][0]['embedding']
# Generate embeddings for all titles
df['embedding'] = df['Title'].apply(get_embedding)
# Create a matrix of embeddings
embedding_matrix = np.vstack(df['embedding'].values)
# Compute cosine similarity matrix
similarity_matrix = cosine_similarity(embedding_matrix)
# Define similarity threshold
similarity_threshold = 0.9 # since threshold is 0.1 for dissimilarity
# Create a list to store groups
groups = []
# Keep track of visited indices
visited = set()
# Group similar titles based on the similarity matrix
for i in range(len(similarity_matrix)):
if i not in visited:
# Find all similar titles
similar_indices = np.where(similarity_matrix[i] >= similarity_threshold)[0]
# Log comparisons
print(f"nChecking similarity for '{df.iloc[i]['Title']}' (Index {i}):")
print("-" * 50)
for j in range(len(similarity_matrix)):
if i != j: # Ensure that a title is not compared with itself
similarity_value = similarity_matrix[i, j]
comparison_result="greater" if similarity_value >= similarity_threshold else 'less'
print(f"Compared with '{df.iloc[j]['Title']}' (Index {j}): similarity = {similarity_value:.4f} ({comparison_result} than threshold)")
# Add these indices to visited
visited.update(similar_indices)
# Add the group to the list
group = df.iloc[similar_indices][['URL', 'Title']].to_dict('records')
groups.append(group)
print(f"nFormed Group {len(groups)}:")
for item in group:
print(f" - URL: {item['URL']}, Title: {item['Title']}")
# Check if groups were created
if not groups:
print("No groups were created.")
# Define the output CSV file
output_file="grouped_pages.csv"
# Write the results to the CSV file with UTF-8 encoding
with open(output_file, 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ['Group', 'URL', 'Title']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for group_index, group in enumerate(groups, start=1):
for page in group:
cleaned_title = clean_text(page['Title']) # Ensure no unwanted symbols in the output
writer.writerow({'Group': group_index, 'URL': page['URL'], 'Title': cleaned_title})
print(f"Writing Group {group_index}, URL: {page['URL']}, Title: {cleaned_title}")
print(f"Output written to {output_file}")
Este código lee un archivo CSV, ‘pages.csv’, que contiene títulos y URL, que puede exportar fácilmente desde su CMS u obtener rastreando el sitio web de un cliente usando Screaming Frog.
Luego, limpia los títulos de caracteres que no son UTF, genera vectores de incrustación para cada título usando la API de OpenAI, calcula la similitud entre los títulos, agrupa títulos similares y escribe los resultados agrupados en un nuevo archivo CSV, ‘grouped_pages.csv. ‘
En la tarea de canibalización de palabras clave, utilizamos un umbral de similitud de 0,9, lo que significa que si la similitud del coseno es inferior a 0,9, consideraremos los artículos como diferentes. Para visualizar esto en un espacio bidimensional simplificado, aparecerá como dos vectores con un ángulo de aproximadamente 25 grados entre ellos.
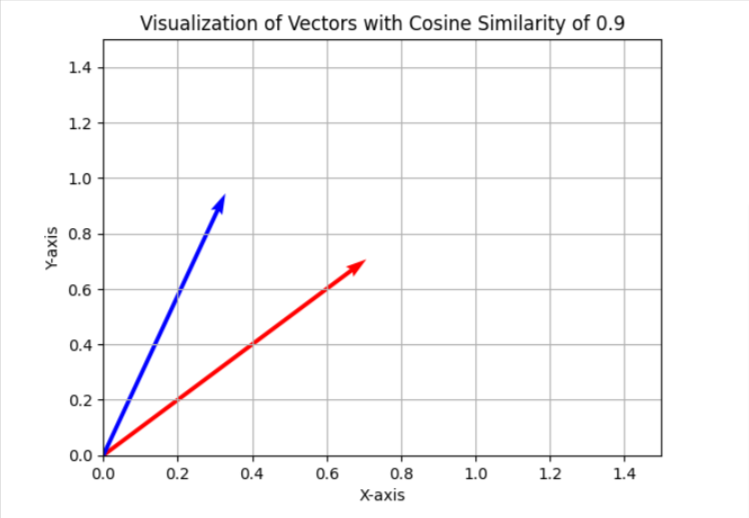
En su caso, es posible que desee utilizar un umbral diferente, como 0,85 (aproximadamente 31 grados entre ellos), y ejecutarlo en una muestra de sus datos para evaluar los resultados y la calidad general de las coincidencias. Si no es satisfactorio, puede aumentar el umbral para hacerlo más estricto y lograr una mayor precisión.
Puede instalar ‘matplotlib’ a través de la terminal.
Y use el código Python a continuación en un cuaderno Jupyter separado para visualizar las similitudes de cosenos en un espacio bidimensional por su cuenta. Intentalo; ¡es divertido!
import matplotlib.pyplot as plt
import numpy as np
# Define the angle for cosine similarity of 0.9. Change here to your desired value.
theta = np.arccos(0.9)
# Define the vectors
u = np.array([1, 0])
v = np.array([np.cos(theta), np.sin(theta)])
# Define the 45 degree rotation matrix
rotation_matrix = np.array([
[np.cos(np.pi/4), -np.sin(np.pi/4)],
[np.sin(np.pi/4), np.cos(np.pi/4)]
])
# Apply the rotation to both vectors
u_rotated = np.dot(rotation_matrix, u)
v_rotated = np.dot(rotation_matrix, v)
# Plotting the vectors
plt.figure()
plt.quiver(0, 0, u_rotated[0], u_rotated[1], angles="xy", scale_units="xy", scale=1, color="r")
plt.quiver(0, 0, v_rotated[0], v_rotated[1], angles="xy", scale_units="xy", scale=1, color="b")
# Setting the plot limits to only positive ranges
plt.xlim(0, 1.5)
plt.ylim(0, 1.5)
# Adding labels and grid
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.grid(True)
plt.title('Visualization of Vectors with Cosine Similarity of 0.9')
# Show the plot
plt.show()
Normalmente uso 0.9 y superior para identificar problemas de canibalización de palabras clave, pero es posible que tengas que configurarlo en 0.5 cuando trabajes con redireccionamientos de artículos antiguos, ya que es posible que los artículos antiguos no tengan artículos casi idénticos que sean más recientes pero parcialmente similares.
También puede ser mejor tener la meta descripción concatenada con el título en caso de redirecciones, además del título.
Entonces, depende de la tarea que estés realizando. Revisaremos cómo implementar redireccionamientos en un artículo separado más adelante en esta serie.
Ahora, revisemos los resultados con los tres modelos mencionados anteriormente y veamos cómo pudieron identificar artículos cercanos de nuestra muestra de datos de los artículos de Search Engine Journal.
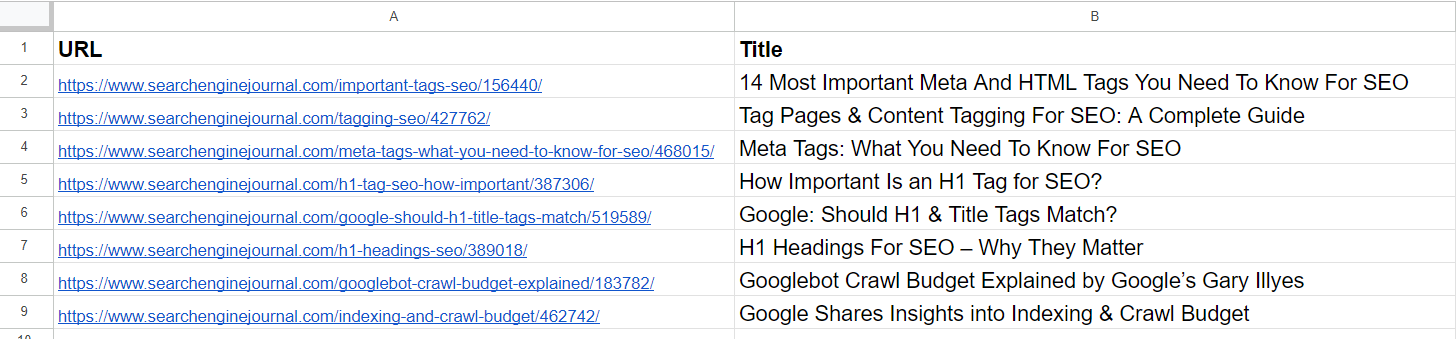 Muestra de datos
Muestra de datosEn la lista, ya vemos que los artículos segundo y cuarto cubren el mismo tema sobre las ‘metaetiquetas’. Los artículos de las filas 5 y 7 son prácticamente iguales (discuten la importancia de las etiquetas H1 en SEO) y se pueden fusionar.
El artículo de la tercera fila no tiene ninguna similitud con ninguno de los artículos de la lista, pero tiene palabras comunes como «Etiqueta» o «SEO».
El artículo de la sexta fila trata nuevamente sobre H1, pero no es exactamente lo mismo que la importancia de H1 para SEO. Más bien, representa la opinión de Google sobre si deberían coincidir.
Los artículos de las filas 8 y 9 son bastante parecidos pero aún diferentes; se pueden combinar.
incrustación-de-texto-ada-002
Al utilizar ‘text-embedding-ada-002’, encontramos con precisión los artículos segundo y cuarto con una similitud de coseno de 0,92 y los artículos quinto y séptimo con una similitud de 0,91.
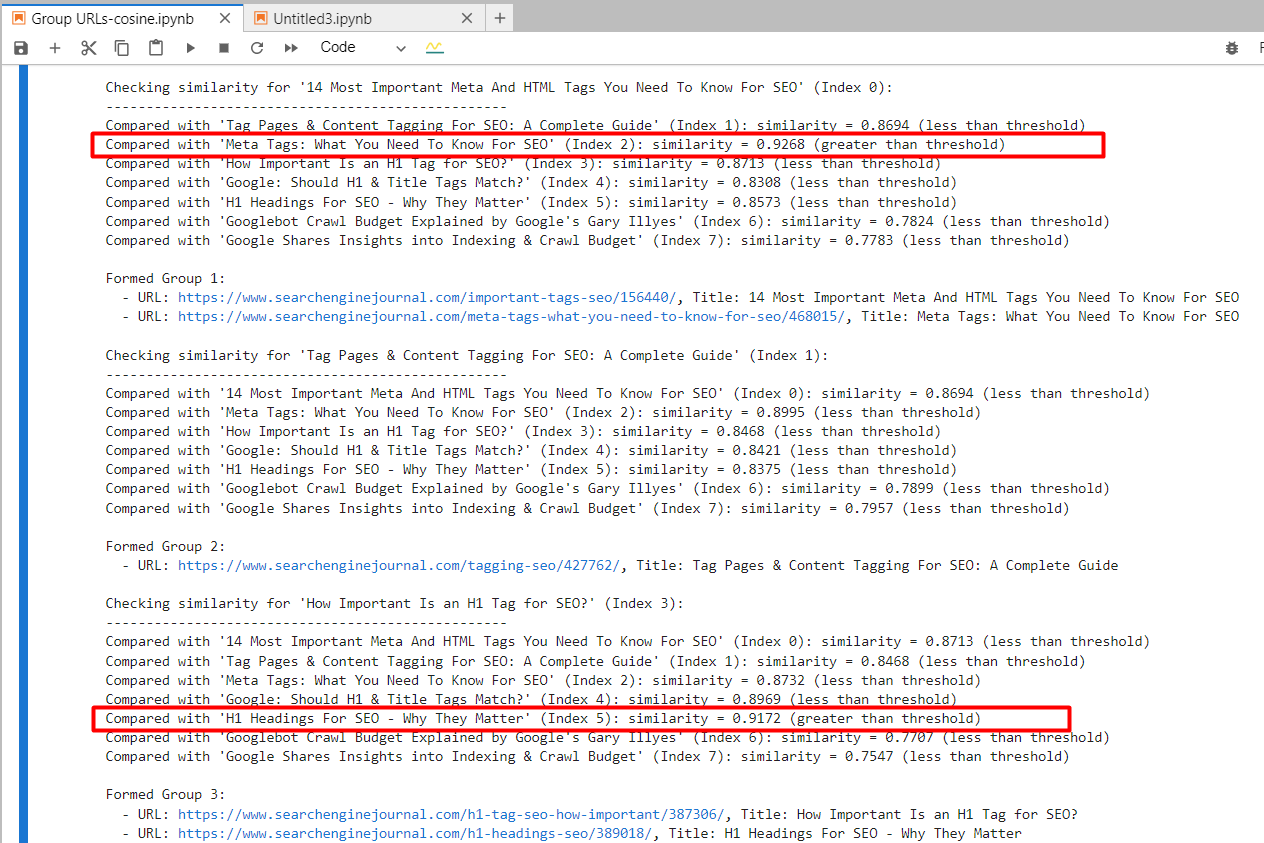 Captura de pantalla del registro de Jupyter que muestra similitudes de cosenos
Captura de pantalla del registro de Jupyter que muestra similitudes de cosenosY generó resultados con URL agrupadas utilizando el mismo número de grupo para artículos similares. (Los colores se aplican manualmente con fines de visualización).
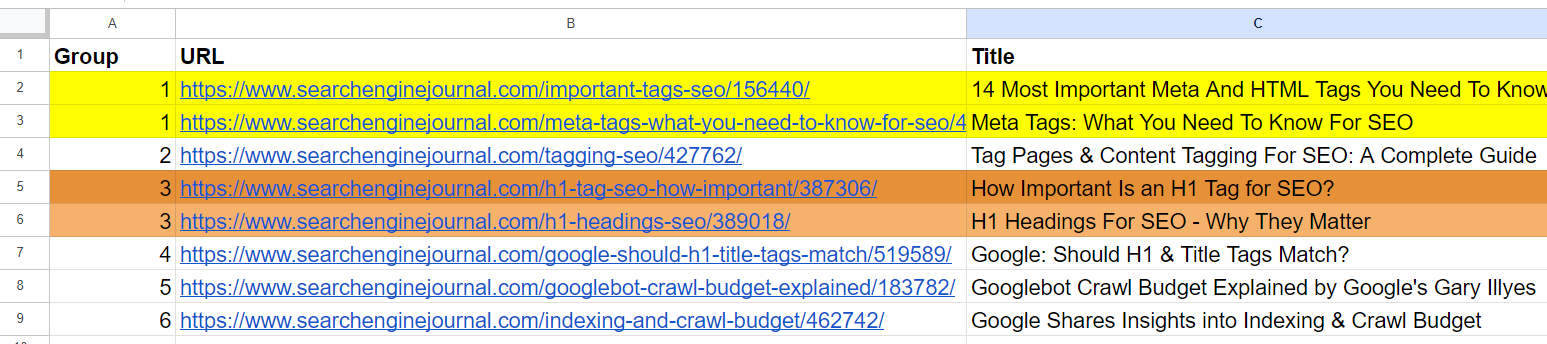 Hoja de salida con URL agrupadas
Hoja de salida con URL agrupadasPara los artículos segundo y tercero, que tienen palabras comunes «Etiqueta» y «SEO» pero no están relacionadas, la similitud del coseno fue de 0,86. Esto muestra por qué es necesario un umbral de similitud alto de 0,9 o más. Si lo configuramos en 0,85, estaría lleno de falsos positivos y podría sugerir la fusión de artículos no relacionados.
incrustación-de-texto-3-pequeño
Al utilizar ‘text-embedding-3-small’, sorprendentemente, no encontró ninguna coincidencia según nuestro umbral de similitud de 0,9 o superior.
Para los artículos 2 y 4, la similitud del coseno fue de 0,76, y para los artículos 5 y 7, con una similitud de 0,77.
Para comprender mejor este modelo a través de la experimentación, agregué una versión ligeramente modificada de la primera fila con ’15’ frente a ’14’ a la muestra.
- «Las 14 metaetiquetas y HTML más importantes que debes conocer para SEO»
- «Las 15 metaetiquetas y HTML más importantes que debes conocer para SEO»
 Un ejemplo que muestra resultados de incrustación de texto-3-pequeños
Un ejemplo que muestra resultados de incrustación de texto-3-pequeñosPor el contrario, ‘text-embedding-ada-002’ dio una similitud de coseno de 0,98 entre esas versiones.
| Título 1 | Título 2 | Similitud del coseno |
| Las 14 metaetiquetas y HTML más importantes que necesitas saber para SEO | 15 Metaetiquetas y HTML más importantes que necesita saber para SEO | 0,92 |
| Las 14 metaetiquetas y HTML más importantes que necesitas saber para SEO | Metaetiquetas: lo que necesita saber para SEO | 0,76 |
Aquí vemos que este modelo no es muy adecuado para comparar títulos.
incrustación-de-texto-3-grande
La dimensionalidad de este modelo es 3072, que es 2 veces mayor que la de ‘text-embedding-3-small’ y ‘text-embedding-ada-002′, con 1536 dimensionalidad.
Como tiene más dimensiones que los otros modelos, podríamos esperar que capture el significado semántico con mayor precisión.
Sin embargo, dio a los artículos segundo y cuarto una similitud de coseno de 0,70 y a los artículos quinto y séptimo de 0,75.
Lo probé nuevamente con versiones ligeramente modificadas del primer artículo con ’15’ frente a ’14’ y sin ‘Más importante’ en el título.
- «Las 14 metaetiquetas y HTML más importantes que debes conocer para SEO»
- «Las 15 metaetiquetas y HTML más importantes que debes conocer para SEO»
- «14 metaetiquetas y HTML que debes conocer para SEO»
| Título 1 | Título 2 | Similitud del coseno |
| Las 14 metaetiquetas y HTML más importantes que necesitas saber para SEO | 15 Metaetiquetas y HTML más importantes que necesita saber para SEO | 0,95 |
| Las 14 metaetiquetas y HTML más importantes que necesitas saber para SEO | 14 |
0,93 |
| Las 14 metaetiquetas y HTML más importantes que necesitas saber para SEO | Metaetiquetas: lo que necesita saber para SEO | 0,70 |
| Las 15 metaetiquetas y HTML más importantes que necesitas saber para SEO | 14 |
0,86 |
Entonces podemos ver que ‘text-embedding-3-large’ tiene un rendimiento inferior en comparación con ‘text-embedding-ada-002’ cuando calculamos las similitudes de cosenos entre títulos.
Quiero señalar que la precisión de ‘text-embedding-3-large’ aumenta con la longitud del texto, pero ‘text-embedding-ada-002’ aún funciona mejor en general.
Otro enfoque podría ser eliminar las palabras vacías del texto. Eliminarlos a veces puede ayudar a centrar las incrustaciones en palabras más significativas, lo que potencialmente mejora la precisión de tareas como los cálculos de similitud.
La mejor manera de determinar si eliminar las palabras vacías mejora la precisión de su tarea y conjunto de datos específicos es probar empíricamente ambos enfoques y comparar los resultados.
Conclusión
Con estos ejemplos, ha aprendido a trabajar con los modelos integrados de OpenAI y ya puede realizar una amplia gama de tareas.
Para los umbrales de similitud, debe experimentar con sus propios conjuntos de datos y ver qué umbrales tienen sentido para su tarea específica ejecutándolos en muestras de datos más pequeñas y realizando una revisión humana del resultado.
Tenga en cuenta que el código que tenemos en este artículo no es óptimo para conjuntos de datos grandes, ya que necesita crear incrustaciones de texto de artículos cada vez que hay un cambio en su conjunto de datos para evaluarlo con otras filas.
Para que sea eficiente, debemos utilizar bases de datos vectoriales y almacenar allí la información de incrustación una vez generada. Muy pronto cubriremos cómo usar bases de datos vectoriales y cambiaremos el ejemplo de código aquí para usar una base de datos vectorial.
Más recursos:
Imagen de portada: BestForBest/Shutterstock



