
El nuevo petróleo no son datos ni atención. Son palabras. El diferenciador para construir modelos de IA de próxima generación es el acceso al contenido cuando se normaliza la potencia informática, el almacenamiento y la energía.
Pero la web ya se está quedando pequeña para saciar el hambre de nuevos modelos.
Algunos ejecutivos e investigadores dicen que la necesidad de la industria de datos de texto de alta calidad podría superar la oferta dentro de dos años, lo que podría ralentizar el desarrollo de la IA.
Incluso los ajustes finos no parecen funcionar tan bien como simplemente construir modelos más potentes. Un estudio de caso de investigación de Microsoft muestra que las indicaciones efectivas pueden superar a un modelo ajustado en un 27%.
Nos preguntamos si el futuro consistirá en muchos modelos pequeños y perfeccionados o en unos pocos modelos grandes que lo abarquen todo. Parece ser lo último.
No hay estrategia de IA sin una estrategia de datos.
Hambrientos de más contenido de alta calidad para desarrollar la próxima generación de grandes modelos de lenguaje (LLM), los desarrolladores de modelos comienzan a pagar por contenido natural y reavivan sus esfuerzos por etiquetar datos sintéticos.
Para los creadores de contenido de cualquier tipo, este nuevo flujo de dinero podría abrir el camino hacia un nuevo modelo de monetización de contenido que incentive la calidad y mejore la web.
Mejore sus habilidades con los conocimientos expertos semanales de Growth Memo. ¡Suscríbete gratis!
KYC: Sí
Si el contenido es el nuevo petróleo, las redes sociales son plataformas petrolíferas. Google invirtió 60 millones de dólares al año en el uso del contenido de Reddit para entrenar sus modelos y mostrar las respuestas de Reddit en la parte superior de las búsquedas. Centavos, si me preguntas.
El director ejecutivo de YouTube, Neal Mohan, envió recientemente un mensaje claro a OpenAI y otros desarrolladores de modelos de que la capacitación en YouTube es prohibida, en defensa de las enormes reservas de petróleo de la compañía.
El New York Times, que actualmente está presentando una demanda contra OpenAI, publicó un artículo afirmando que OpenAI desarrolló Whisper para entrenar modelos en transcripciones de YouTube, y Google usa contenido de todas sus plataformas, como Google Docs y reseñas de Maps, para entrenar su IA. modelos.
Los proveedores de datos de IA generativa como Appen o Scale AI están reclutando escritores (humanos) para crear contenido para la capacitación del modelo LLM.
No se equivoque, los escritores no se están haciendo ricos escribiendo para IA.
Por entre 25 y 50 dólares la hora, los escritores realizan tareas como clasificar las respuestas de la IA, escribir cuentos y verificar hechos.
Los solicitantes deben tener un doctorado. o maestría o actualmente asiste a la universidad. Los proveedores de datos claramente buscan expertos y “buenos” escritores. Pero las primeras señales son prometedoras: escribir para IA podría ser monetizable.
 Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin Indig Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin IndigLos desarrolladores de modelos buscan buen contenido en todos los rincones de la web y algunos están felices de venderlo.
Las plataformas de contenido como Photobucket venden fotografías entre cinco centavos y un dólar cada una. Los vídeos de formato corto pueden costar entre 2 y 4 dólares; las películas más largas cuestan entre 100 y 300 dólares por hora de metraje.
Con miles de millones de fotografías, la empresa encontró petróleo en su patio trasero. ¿Qué director ejecutivo puede resistir tal tentación, especialmente ahora que la monetización de contenidos es cada vez más difícil?
De contenido gratuito:
Los editores están siendo presionados por múltiples lados:
- Pocos están preparados para la muerte de las cookies de terceros.
- Las redes sociales envían menos tráfico (Meta) o deterioran su calidad (X).
- La mayoría de los jóvenes reciben noticias de TikTok.
- SGE aparece en el horizonte.
Irónicamente, etiquetar mejor el contenido de IA podría ayudar al desarrollo de un LLM porque es más fácil separar el contenido natural del sintético.
En ese sentido, a los desarrolladores de LLM les interesa etiquetar el contenido de IA para poder excluirlo de la capacitación o usarlo de la manera correcta.
Etiquetado
Buscar palabras para capacitar a los LLM es solo una cara del desarrollo de modelos de IA de próxima generación. El otro es el etiquetado. Los desarrolladores de modelos necesitan un etiquetado para evitar el colapso de los modelos, y la sociedad lo necesita como escudo contra las noticias falsas.
Está surgiendo un nuevo movimiento de etiquetado de IA a pesar de que OpenAI abandonó las marcas de agua debido a su baja precisión (26%). En lugar de etiquetar el contenido ellos mismos, lo que parece inútil, las grandes tecnologías (Google, YouTube, Meta y TikTok) empujan a los usuarios a etiquetar el contenido de IA con un enfoque de zanahoria/palo.
Google utiliza un enfoque doble para combatir el spam de IA en las búsquedas: mostrar de manera destacada foros como Reddit, donde lo más probable es que el contenido sea creado por humanos, y aplicar sanciones.
De AIfficiency:
Google está mostrando más contenido en los foros de las SERP para contrarrestar el contenido de IA. La verificación es lo último en marcas de agua de IA. Aunque Reddit no puede evitar que los humanos usen IA para crear publicaciones o comentarios, las posibilidades son menores debido a dos cosas que la búsqueda de Google no tiene: moderación y karma.
Sí, Content Goblins ya ha apuntado a Reddit, pero la mayoría de los 73 millones de usuarios activos diarios brindan respuestas útiles.1 Los moderadores de contenido castigan el spam con prohibiciones o incluso patadas. Pero el impulsor de calidad más poderoso en Reddit es Karma, «la puntuación de reputación de un usuario que refleja sus contribuciones a la comunidad». A través de simples votos a favor o en contra, los usuarios pueden ganar autoridad y confiabilidad, dos ingredientes integrales en los sistemas de calidad de Google.
Google aclaró recientemente que espera que los comerciantes no eliminen los metadatos de IA de las imágenes utilizando el protocolo de metadatos IPTC.
Cuando una imagen tiene una etiqueta como compositeSynthetic, Google puede etiquetarla como “generada por IA” en cualquier lugar, no solo en las compras. El castigo por eliminar metadatos de IA no está claro, pero lo imagino como una penalización de enlace.
IPTC es el mismo formato que utiliza Meta para Instagram, Facebook y WhatsApp. Ambas empresas asignan metaetiquetas IPTC a cualquier contenido que surja de sus propios LLM. Cuanto más sigan los fabricantes de herramientas de IA las mismas pautas para marcar y etiquetar el contenido de IA, más confiables funcionarán los sistemas de detección.
Cuando se crean imágenes fotorrealistas utilizando nuestra función Meta AI, hacemos varias cosas para asegurarnos de que las personas sepan que la IA está involucrada, incluida la colocación de marcadores visibles que se pueden ver en las imágenes y marcas de agua invisibles y metadatos incrustados en los archivos de imagen. El uso de marcas de agua invisibles y metadatos de esta manera mejora la solidez de estos marcadores invisibles y ayuda a otras plataformas a identificarlos.
Las desventajas del contenido de IA son pequeñas cuando el contenido parece IA. Pero cuando el contenido de IA parece real, necesitamos etiquetas.
Mientras que los anunciantes intentan alejarse de la apariencia de la IA, las plataformas de contenido la prefieren porque es fácil de reconocer.
Para los artistas comerciales y anunciantes, la IA generativa tiene el poder de acelerar enormemente el proceso creativo y ofrecer anuncios personalizados a los clientes a gran escala, algo así como un santo grial en el mundo del marketing. Pero hay un problema: muchas imágenes que generan los modelos de IA presentan una suavidad caricaturesca, defectos reveladores o ambas cosas.
Los consumidores ya se están volviendo contra “la apariencia de la IA”, hasta el punto de que un extraño y cinematográfico anuncio del Super Bowl de la organización benéfica cristiana He Gets Us fue acusado de haber nacido de la IA, a pesar de que un fotógrafo creó sus imágenes.
YouTube comenzó a aplicar nuevas pautas para los creadores de videos que dicen que el contenido de IA que parezca realista debe etiquetarse.
Los desafíos que plantea la IA generativa han sido un área de atención constante para YouTube, pero sabemos que la IA introduce nuevos riesgos que los malos actores pueden intentar explotar durante una elección. La IA se puede utilizar para generar contenido que tiene el potencial de engañar a los espectadores, especialmente si no saben que el vídeo ha sido alterado o creado sintéticamente. Para abordar mejor esta inquietud e informar a los espectadores cuando el contenido que están viendo esté modificado o sea sintético, comenzaremos a introducir las siguientes actualizaciones:
- Divulgación del creador: Los creadores deberán revelar cuándo han creado contenido alterado o sintético que sea realista, incluido el uso de herramientas de inteligencia artificial. Esto incluirá contenido electoral.
- Etiquetado: Etiquetaremos contenido electoral realista, alterado o sintético, que no infrinja nuestras políticas, para indicar claramente a los espectadores que parte del contenido fue alterado o sintético. Para las elecciones, esta etiqueta se mostrará tanto en el reproductor de video como en la descripción del video, y aparecerá independientemente del creador, los puntos de vista políticos o el idioma.
El mayor temor inminente es el contenido falso de IA que podría influir en las elecciones presidenciales estadounidenses de 2024.
Ninguna plataforma quiere ser el Facebook de 2016, que sufrió un daño duradero a su reputación que afectó el precio de sus acciones.
Los actores estatales chinos y rusos ya han experimentado con noticias falsas sobre inteligencia artificial y han intentado entrometerse en las elecciones taiwanesas y en las próximas elecciones estadounidenses.
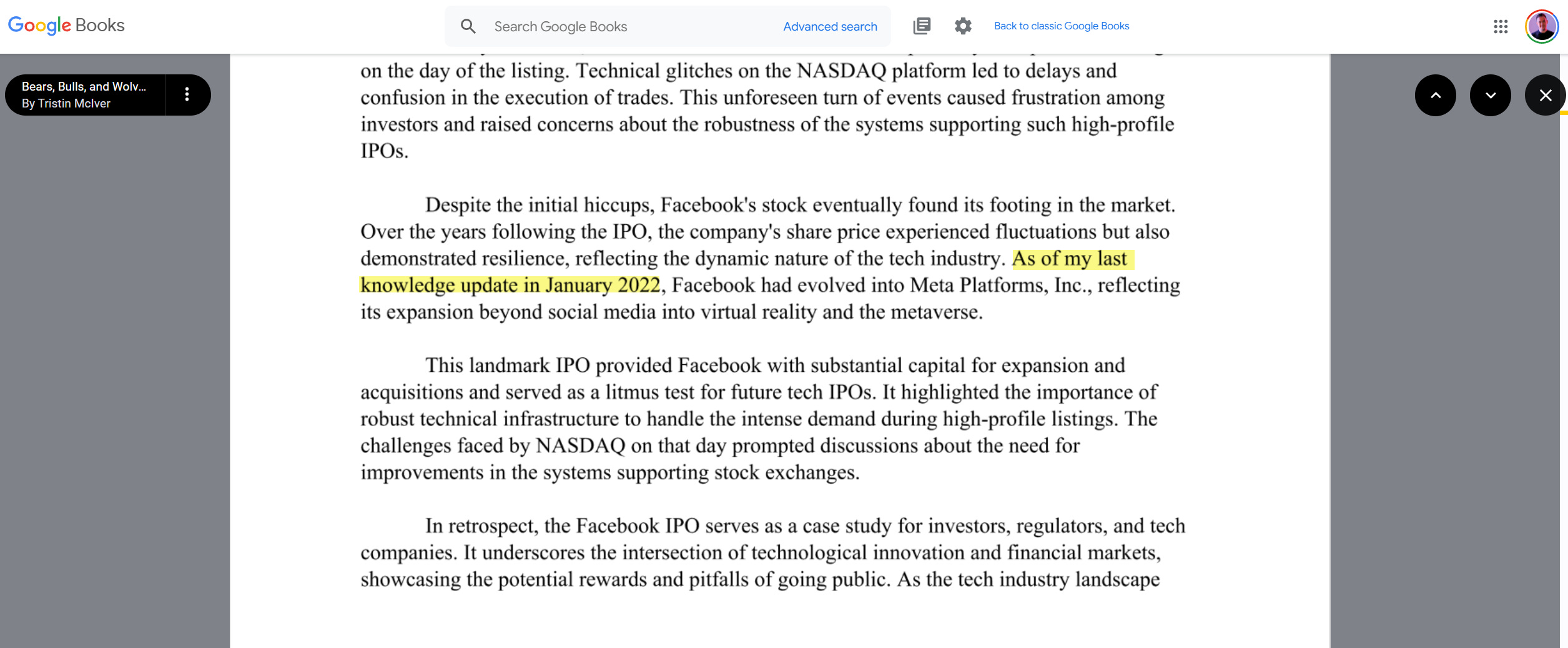
Ahora que OpenAI está cerca de lanzar Sora, que crea videos hiperrealistas a partir de indicaciones, no es muy difícil imaginar cómo los videos de IA pueden causar problemas sin un etiquetado estricto. Es difícil controlar la situación. Google Books ya incluye libros que fueron claramente escritos con o por ChatGPT.
 Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin IndigLlevar
Las etiquetas, ya sean mentales o visuales, influyen en nuestras decisiones. Marcan el mundo para nosotros y tienen el poder de crear o destruir confianza. Al igual que la heurística de categorías en las compras, las etiquetas simplifican nuestra toma de decisiones y el filtrado de información.
De Medio desordenado:
Por último, la idea de la heurística de categorías, números en los que los clientes se centran para simplificar la toma de decisiones, como megapíxeles para las cámaras, ofrece un camino para especificar la optimización del comportamiento del usuario. Una tienda de comercio electrónico que vende cámaras, por ejemplo, debería optimizar sus tarjetas de productos para priorizar visualmente la heurística de categorías. Por supuesto, primero debe comprender las heurísticas de sus categorías, y pueden variar según el producto que venda. Supongo que eso es lo que se necesita para tener éxito en SEO hoy en día.
Pronto, las etiquetas nos dirán cuándo el contenido está escrito por IA o no. En una encuesta pública a 23.000 encuestados, Meta descubrió que el 82% de las personas quieren etiquetas en el contenido de IA. Queda por ver si las normas y castigos comunes funcionan, pero la urgencia está ahí.
Aquí también existe una oportunidad: las discográficas podrían destacar a los escritores humanos y hacer que su contenido sea más valioso, dependiendo de qué tan bueno sea el contenido de IA.
Además, escribir para IA podría ser otra forma de monetizar el contenido. Si bien las tarifas por hora actuales no enriquecen a nadie, la capacitación modelo agrega nuevo valor al contenido. Las plataformas de contenidos podrían encontrar nuevas fuentes de ingresos.
El contenido web se ha vuelto extremadamente comercializado, pero las licencias de IA podrían incentivar a los escritores a crear buen contenido nuevamente y desvincularse de los ingresos publicitarios o de afiliados.
A veces, el contraste hace visible el valor. Quizás la IA pueda mejorar la web después de todo.
Para las empresas de inteligencia artificial que consumen muchos datos, Internet es demasiado pequeña
El poder de incitar
Dentro de la carrera clandestina de las grandes tecnologías para comprar datos de entrenamiento de IA
OpenAI renuncia a la herramienta de detección de texto generado por IA
Metadatos de fotografías IPTC
Etiquetado de imágenes generadas por IA en Facebook, Instagram e hilos
Cómo la industria publicitaria está haciendo que las imágenes de IA se parezcan menos a la IA
Cómo ayudamos a los creadores a divulgar contenido modificado o sintético
Abordar la desinformación electoral generada por IA
China está apuntando a los votantes estadounidenses y a Taiwán con desinformación impulsada por la IA
Google Books está indexando basura generada por IA
Nuestro enfoque para etiquetar contenido generado por IA y medios manipulados
Imagen de portada: Paulo Bobita/Search Engine Journal



