
Barry Pollard de Google hizo una larga explicación sobre Bluesky sobre por qué Google Search Console dice que un LCP es malo, pero las URL individuales están bien. No quiero estropearlo, así que copiaré lo que Barry escribió.
Esto es lo que escribió en varias publicaciones en Bluesky:
Core Web Vitals Mystery para ti:
¿Por qué la consola de búsqueda de Google mismo mi LCP es malo, pero cada URL de ejemplo tiene un buen LCP?
Veo que los desarrolladores preguntan: ¿Cómo puede suceder esto? ¿GSC está equivocado? (¡Estoy dispuesto a apostar que no lo es!) ¿Qué puedes hacer al respecto?
Esto es ciertamente confuso, así que vamos a sumergirnos en …
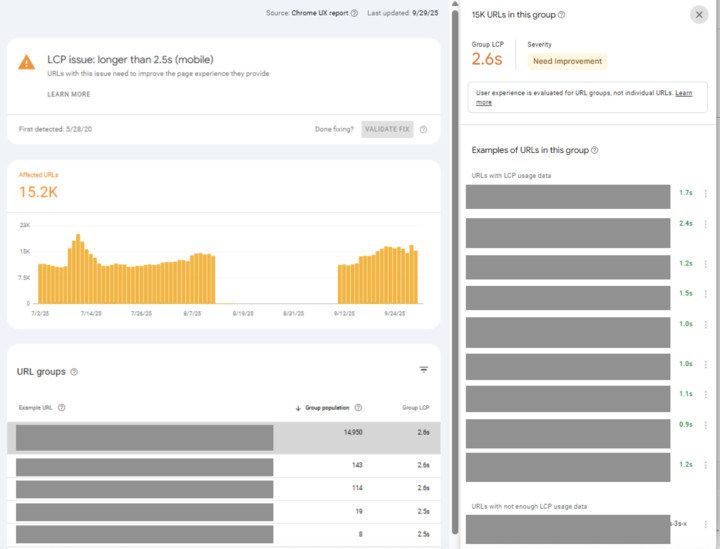
Primero, es importante comprender cómo este informe y Crux miden vitales de la Web Core, porque una vez que lo haga, es más comprensible, aunque aún deja la pregunta de lo que puede hacer al respecto (llegaremos a eso).
El problema es similar a este hilo anterior:
«¿Cómo es posible que Crux diga que el 90% de las cargas de la página son buenas, y la consola de búsqueda de Google para decir que solo el 50% de las URL son buenas? ¿Cuál es correcto?»
Es una pregunta que recibo sobre los vitales de la web central y admito que es confuso, pero la verdad es que ambos son correctas porque son medidas diferentes …
1/5 🧵
– Barry Pollard (@tunetheweb.com) 19 de agosto de 2025 a las 6:32 am
Cargas de la página de medidas de Crux y el número Core Web Vitals es el percentil 75 de esas cargas de página.
Esa es una forma elegante de decir: «La puntuación que la mayoría de las vistas de la página obtienen al menos» – Whee «Most» es del 75%.
Philip Walton lo cubre más en este video:
https://www.youtube.com/watch?v=fwoi9dxmpdk
Para un sitio de comercio electrónico con muchos productos, tendrá algunos productos muy populares (¡con muchas vistas de página!), Y luego una cola larga y larga de muchas, muchas páginas menos populares (con una pequeña cantidad de vistas de página).
El problema surge cuando la cola larga se suma a más del 25% de las vistas de su página total.
Es más probable que los populares tengan datos de quid a nivel de página (solo nos damos los datos cuando cruzamos un umbral no público), por lo que es más probable que se muestren como ejemplos en GSC debido a eso.
Ellos también son los que probablemente debería concentrarse: ¡son los que obtienen el tráfico!
Pero las páginas populares tienen otro sesgo interesante: ¡a menudo son más rápidos!
¿Por qué? Porque a menudo se almacenan en caché. En cachés DB, en cachés de barniz, y especialmente en nodos de borde CDN.
Las páginas de cola larga tienen mucho más probabilidades de requerir una carga de página completa, omitir todos esos cachés, por lo que será más lento.
Esto es cierto incluso si las páginas se basan en la misma tecnología y se optimizan exactamente de la misma manera con las mismas técnicas de codificación e imágenes optimizadas … etc.
¡Los cachés son geniales! Pero pueden enmascarar la lentitud que solo se ve para «fallas de caché».
Y esta es a menudo la razón por la que ves esto en GSC.
Entonces, ¿cómo arreglar?
Siempre habrá un límite para los tamaños de caché y los cachés de cebado para páginas poco visitadas no tiene mucho sentido, por lo que debe reducir el tiempo de carga de las páginas sin dejar consignas.
El almacenamiento en caché debe ser una «cereza en la parte superior» para aumentar la velocidad, en lugar de la única razón por la que tiene un sitio rápido.
Una forma en que me gusta verificar esto es agregar un parámetro de URL aleatorio a una URL (por ejemplo, test = 1234) y luego volver a ejecutar una prueba de faro que cambia el valor cada vez. Por lo general, esto resulta en recuperar una página sin dejar de lado.
Compare eso con una página en caché (ejecutando la URL normal un par de veces).
Si es mucho más lento, ahora entiendes la diferencia entre tu caché y tu descenso y puedes comenzar a pensar en formas de mejorar eso.
Idealmente, lo obtienes por debajo de 2.5 segundos incluso sin caché, ¡y tus páginas populares (en caché) son simplemente aún más rápidas!
Por cierto, esta también puede ser la razón por la cual las campañas publicitarias (con parámetros UTM aleatorios y similares) también pueden ser más lentos.
Puede configurar CDN para ignorarlos y no tratarlos como nuevas páginas. También hay un próximo estándar para permitir que una página especifique qué parámetros no importan:
Esto es genial y ha estado esperando que la búsqueda no variada escape de las reglas de especulación (donde esto se inició originalmente) al caso de uso más general.
Esto le permite decir que ciertos parámetros de URL del lado del cliente (por ejemplo, GCLID u otros parámetros analíticos) pueden ignorarse y aún usar el recurso desde el caché.
[image or embed]
– Barry Pollard (@tunetheweb.com) 26 de septiembre de 2025 a las 11:57 am
Discusión del foro en Bluesky.


")
