
Mejore sus habilidades con los conocimientos expertos semanales de Growth Memo. ¡Suscríbete gratis!
La estrategia de Perplexity detrás de su nueva función Páginas creó una profunda brecha con los editores, pero la reacción parece desproporcionada. Es mucho más interesante como un estudio de caso para contenido de IA dirigido al usuario (UDC en lugar de UGC).
Perplexity Pages permite a los usuarios «crear artículos completos y bellamente diseñados sobre cualquier tema». Puede convertir un hilo, una secuencia de mensajes, en una página sobre un tema.
Como lector habitual de Growth Memo, comprenderá rápidamente que se trata de una estrategia de crecimiento en la que, idealmente, los usuarios crean contenido de IA que se clasifica en la búsqueda orgánica y atrae visitantes a perplexity.ai que se convierte en suscriptores de pago.
La estrategia de crecimiento encaja en lo que el director ejecutivo Srinivas explica como «un agregador de información». Tiene poder al brindar una experiencia de usuario superior, lo que le permite canalizar la demanda y mercantilizar la oferta.
Una gota en la cubeta
Cuando miramos los datos reales, podemos ver que la reacción de los medios es exagerada. No en la crítica sino en el impacto. Es justo pedirle a Perplexity que ajuste la atribución, siga estándares web como robots.txt y utilice IP oficiales como también lo hacen los motores de búsqueda.
Según el desarrollador Ryan Knight, Perplexity rastrea la web con un navegador sin cabeza que enmascara su cadena IP.
El director ejecutivo Srinivas dijo que Perplexity obedece a robots.txt y que la IP enmascarada proviene de un servicio de terceros. Pero también mencionó que “el surgimiento de la IA requiere un nuevo tipo de relación de trabajo entre los creadores o editores de contenido y sitios como el suyo”.
Pero en términos de beneficios para Perplexity, Pages es una gota en el océano.
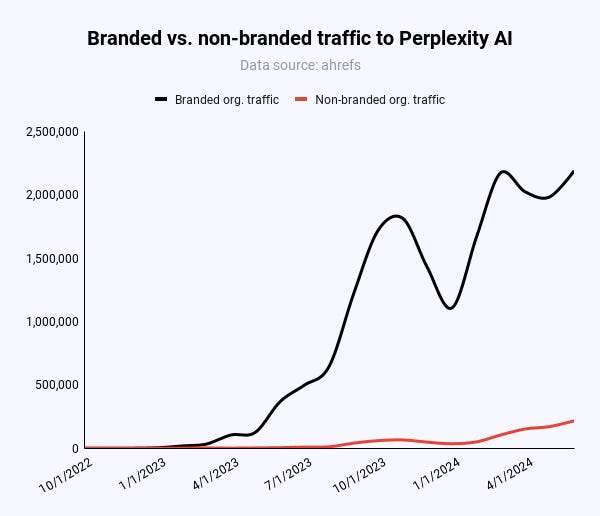
El 91% del tráfico orgánico a perplejidad.ai proviene de términos de marca como «perplejidad».
Sólo 47.000 de 217.000 (21,6%) visitantes mensuales a las páginas provienen de palabras clave orgánicas sin marca a nivel mundial.
En Estados Unidos, es el 55% (20.000/36.000). Sin embargo, en comparación con x visitas mensuales de términos de marca, Pages no afecta el tráfico orgánico de Perplexity.
 Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin IndigEn realidad, la mayor parte del tráfico hacia Perplexity proviene de su marca y del boca a boca. La reciente cobertura mediática podría haber ayudado a Perplejidad más que perjudicado. El sitio ha alcanzado nuevos máximos históricos de tráfico todos los días desde enero de 2024, según Similarweb.
Todo el dominio de Perplexity tiene sólo 950 páginas., de las cuales las páginas representan casi 600. En comparación con otros sitios, como los 6,8 millones de artículos de Wikipedia sólo en la versión en inglés, eso no es mucho. Surgirán efectos de escala más fuertes a medida que las páginas ganen más tracción. En este momento, Pages es una función beta incipiente.
Si analizamos más de cerca su rendimiento, las páginas de palabras clave más buscadas se encuentran entre las tres primeras porque «fue Candy Montgomery culpable» (600 MSV). La palabra clave más difícil para la que ocupa la primera posición es «cuándo fue la primera compra de bitcoins» (KD: 76, MSV: 30). En otras palabras, a Pages todavía le queda un largo camino por recorrer.
Se muestra una comparación de similitud de texto n=1 (!) con GoTranscript entre la página de Perplexity para el «día de la pizza bitcoin» y sus cuatro fuentes vinculadas. poca evidencia de plagio:
- nationaltoday.com/bitcoin-pizza-day/ (15% de similitud).
- www.uledger.io/post/bitcoin-pizza-day-history (27% de similitud).
- coinedition.com/bitcoin-pizza-day-a-700-million-reminder-of-cryptocurrencys-rise/ (15%).
- www.investopedia.com/news/bitcoin-pizza-day-celebrating-20-million-pizza-order/ (9%).
 Comparación de texto entre el artículo de Perplexity y NationalToday sobre el Día de la Pizza Bitcoin (Crédito de la imagen: Kevin Indig)
Comparación de texto entre el artículo de Perplexity y NationalToday sobre el Día de la Pizza Bitcoin (Crédito de la imagen: Kevin Indig)El problema de atribución «faltante» parece haberse solucionado, como muestra el siguiente ejemplo.
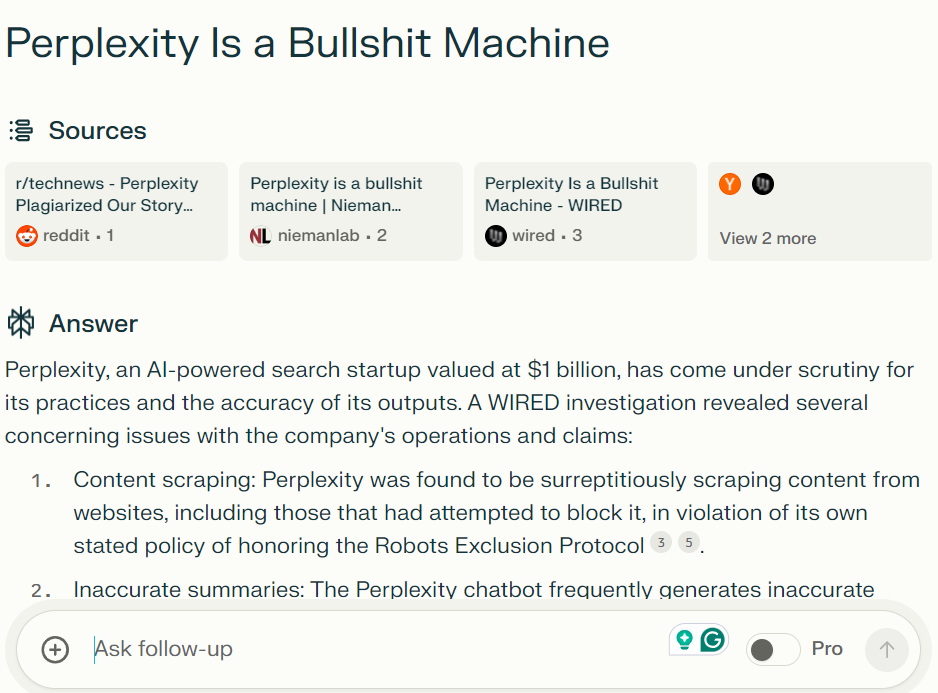 Perplejidad destaca las fuentes de respuestas en la parte superior (Crédito de la imagen: Kevin Indig)
Perplejidad destaca las fuentes de respuestas en la parte superior (Crédito de la imagen: Kevin Indig)Los resultados mostraron que el chatbot a veces parafraseaba estrechamente las historias de WIRED y, a veces, las resumía de manera inexacta y con una atribución mínima.
No pude confirmar ni negar casos de alucinaciones, pero espero que mejores modelos lleguen a un punto en el que puedan resumir el contenido existente sin problemas. La realidad es que todavía no hemos llegado a ese punto. También se ha demostrado que las descripciones generales de IA de Google incluyen datos erróneos o invenciones.
Google parece haber podido solucionar el problema rápidamente, por lo que espero que el grado de alucinaciones disminuya.
Una cuestión subyacente de la crítica del plagio es que una búsqueda del título exacto de un artículo arroja ese artículo.
Por supuesto, Perplexity debería devolver un resumen de un artículo cuando los usuarios lo soliciten. ¿Qué más debería mostrar Perplejidad? El mismo argumento surgió en la demanda entre OpenAI y el NY Times.
Motivado
Además de los problemas que Perplexity necesita solucionar, la reacción de los medios parece ser provocada por el posicionamiento de Perplexity.
Una frase en el anuncio de Pages por parte de Perplexity llega al meollo del problema subyacente:
«Con Pages, no es necesario ser un escritor experto para crear contenido de alta calidad».
La página también menciona:
”Crear contenido que resuene puede resultar difícil. Pages está diseñado para brindar claridad, dividiendo temas complejos en partes digeribles y sirviendo a todos, desde educadores hasta ejecutivos”.
Todos los ejemplos de páginas enumeradas en el anuncio tratan sobre temas de «cómo» o «qué es»:
- “Guía para principiantes sobre la batería”
- “Cómo utilizar un AeroPress”
- “Escribiendo CronJobs de Kubernetes”
- “Steve Jobs: CEO visionario”
- Etc.
Ese es exactamente el desafío que la IA plantea a los escritores: la IA puede cubrir cada vez más formatos de contenido claramente definidos, como guías o tutoriales. Puedo ver cómo esto es desencadenante para los periodistas.
Contenido dirigido al usuario
Observe cómo Perplexity no crea todo el contenido de Pages, sino que toma dirección de los humanos a través de indicaciones (UDC).
En lugar de escribir un artículo completo, los humanos juntan las piezas del rompecabezas y la biografía del autor estampa en una página.
Espero que suceda lo mismo con otros tipos de contenido, como reseñas y plataformas como Google, Tripadvisor, Yelp, G2 & Co. para proporcionar las herramientas correspondientes que faciliten la creación de contenido. El mayor desafío será mantener una alta calidad y reducir al mínimo la información inútil.
La gran pregunta es si una creación como Pages puede competir con un sitio escrito puramente por humanos como Wikipedia, que actualmente cuenta con 116.000 contribuyentes activos.
El mayor “juego de crecimiento” detrás de las páginas (en mi humilde opinión) es cómo Perplexity crea podcasts de IA (video) a partir de artículos resumidos que superan a los resultados originales.
“Luego, Perplexity envió esta historia falsa a sus suscriptores a través de una notificación automática móvil. Creó un podcast generado por IA utilizando los mismos informes (Forbes), sin ningún crédito para Forbes, y se convirtió en un vídeo de YouTube que supera todo el contenido de Forbes sobre este tema en la búsqueda de Google”.
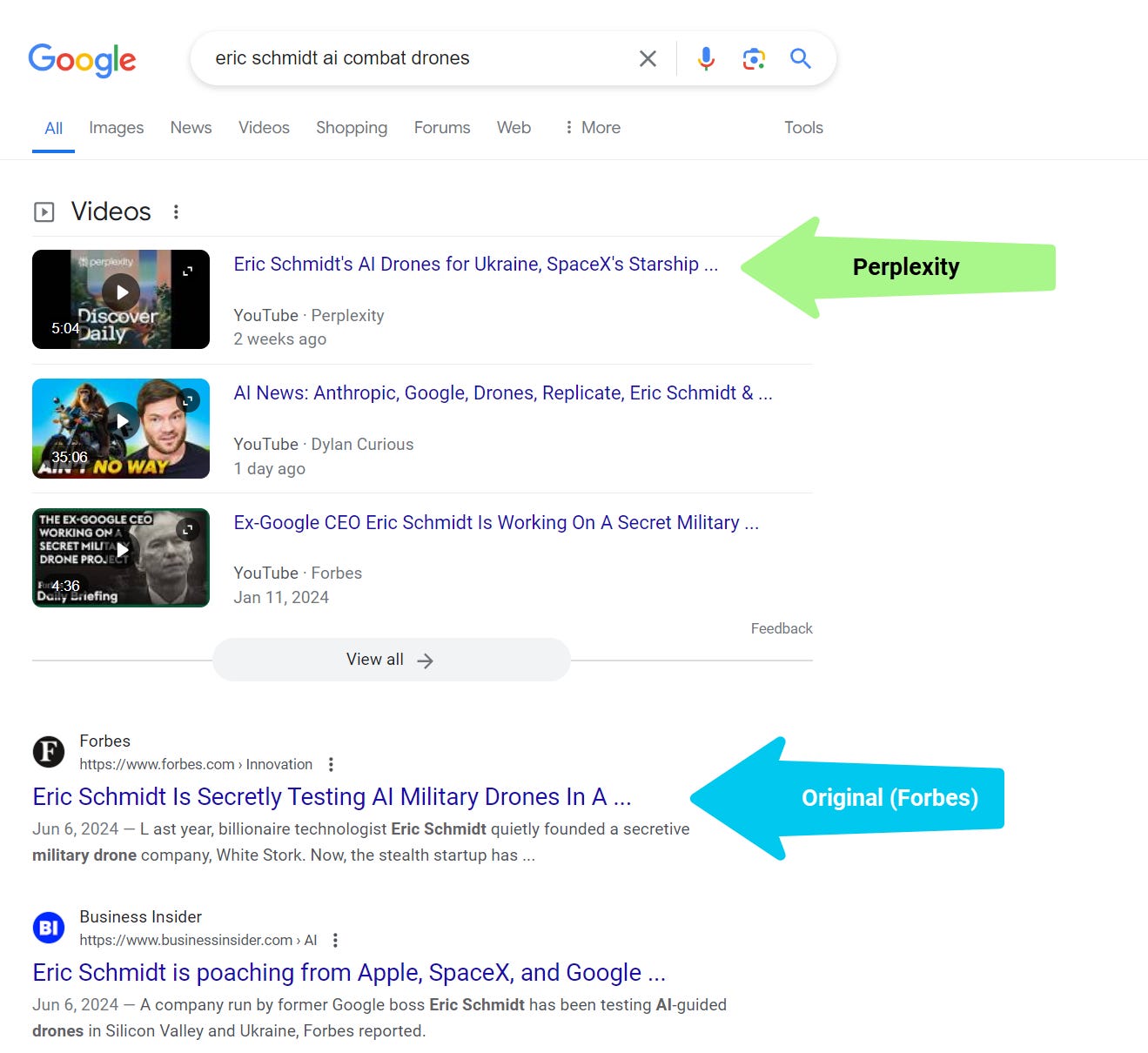 La perplejidad supera a los editores con podcasts de vídeo que resumen artículos (Crédito de la imagen: Kevin Indig)
La perplejidad supera a los editores con podcasts de vídeo que resumen artículos (Crédito de la imagen: Kevin Indig)Google tendrá que descubrir cómo evitar que los LLM reutilicen el contenido de los editores.
Lo que queda después de examinar los hechos es darse cuenta de lo difícil que es equilibrar dar una respuesta de IA y enviar tráfico a las fuentes. ¿Por qué los usuarios deberían hacer clic cuando la mayoría de sus preguntas han sido respondidas?
En la otra cara de la moneda, los propios editores pueden proporcionar resúmenes de sus artículos. Por lo tanto, el desafío clave para Perplexity (y para cualquiera que quiera crear contenido de IA a gran escala para la Búsqueda) es agregar valor único además de los resúmenes de IA.
El camino hacia el valor único de los resúmenes de IA y otros contenidos de IA es personalización.
Un sistema que pueda reconocer sus preferencias en cuanto al nivel de comprensión de un tema puede hacer que los resúmenes de IA le resulten más útiles. Perplexity es un envoltorio de diferentes LLM, pero si recopila información importante sobre los usuarios y personaliza los resultados, puede agregar valor más allá de las respuestas rápidas.
Los fabricantes de sistemas operativos de dispositivos como Alphabet y Apple tienen la mayor ventaja en lo que respecta a los datos de los usuarios, ya que se encuentran en la cima de la cadena alimentaria.
Un buen ejemplo es Apple Intelligence, que probablemente podría responder las preguntas que actualmente brindan las guías y tutoriales de Google o Perplexity.
Apple Intelligence (abreviado “AI”, ¡bueno, Apple!) tiene contexto completo a través de la ubicación (Apple Maps), el uso de aplicaciones de terceros, indicaciones de Siri, correo electrónico (Apple Mail) y otras fuentes, lo que crea una buena base para personalizar. resultados en. La Web es sólo un conjunto de conocimientos, con uno mucho más atractivo esperando en nuestra bandeja de entrada de Dropbox, Gmail y en las fotos del iPhone.
Hoy, las respuestas personalizadas son una visión y una demostración.
Pero en algún momento en el futuro, la personalización creará mejores respuestas que cualquier resumen genérico de LLM y seguramente más que cualquier guía escrita por humanos.
El valor del conocimiento definido y genérico está en curso de colisión con los bombarderos LLM. Al mismo tiempo, el valor del conocimiento personalizado, la experiencia humana y la experiencia de expertos confiables se está disparando.
La startup de inteligencia artificial Perplexity quiere revolucionar el negocio de las búsquedas. El medio de noticias Forbes dice que los está estafando; Crecimiento integrador versus agregador
Perplexity AI miente sobre su agente de usuario
El director ejecutivo de Perplexity, Aravind Srinivas, responde a las acusaciones de plagio e infracción
¿Qué son las páginas de perplejidad?
Presentamos las páginas de perplejidad
Wikipedia: Acerca de
Por qué el cínico robo de Perplexity representa todo lo que podría salir mal con la IA
Imagen de portada: Paulo Bobita/Search Engine Journal



