
Hay muchas personas en la comunidad que dice que la implementación de datos / esquema estructurados en sus páginas lo ayudará con la visibilidad de búsqueda de IA. Pero pocos realmente lo han probado hasta ahora. Y esas pocas pruebas muestran que agregar datos / esquema estructurados no ayuda con su visibilidad en la búsqueda de IA, al menos aún no.
El primero en probar esto fue Mark Williams-Cook, quien publicó en LinkedIn, un experimento que realizó donde publicó una «explicación visual de por qué su LLM favorito no usa el esquema en sus datos de entrenamiento básicos». Explicó cómo cuando los LLM procesan la página, en realidad «destruye» el marcado de esquema y, por lo tanto, no lo usa.
Él escribió:
LLMS trabaja por «tokenizar» contenido. Eso significa tomar secuencias comunes de caracteres que se encuentran en el texto y acuñar un «token» único para ese conjunto. El LLM luego toma miles de millones de «ventanas» de muestra de conjuntos de estos tokens para construir una predicción sobre lo que viene a continuación.
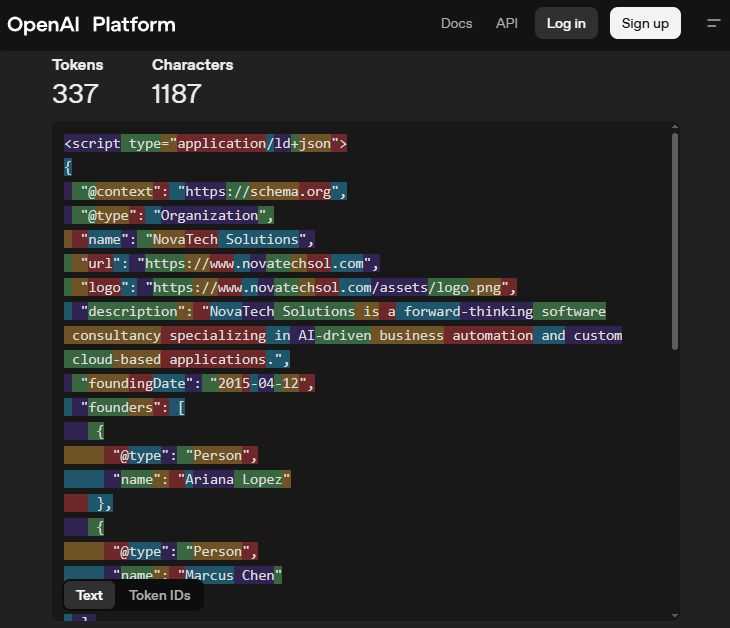
La siguiente imagen es un esquema de ejemplo que tiene un cambio de color aplicado que representa que el conjunto de caracteres es un token único realizado por el modelo GPT-4O.
Lo que notará es que el esquema se «destruye». Por ejemplo, el esquema «@Type»: «organización», se descompone para que hay tokens separados para el «tipo» y la «organización», lo que significa que en términos de tokenización las palabras regulares «tipo» y «organización» no se pueden distinguir del esquema.
Si el esquema se incluyó en estos datos de capacitación, todo lo que haría en realidad es decir que hay una probabilidad ligeramente (probablemente insignificante) de tokens como «@ aparecer antes de la palabra» contenido «.
Aquí está su captura de pantalla:
Si eso no es lo suficientemente bueno para usted, Julio C. Guevara también lo probó y también escribió sobre su prueba en LinkedIn. Él dijo: «Configuramos dos páginas de productos del mismo producto inventado que tanto Gemini como Chatgpt nunca habían visto antes. Una página tenía todo el contenido visible en el HTML como datos estructurados de texto +, la otra página solo tenía datos estructurados y de lo contrario nada visible como texto (visualmente vacío)».
El resultado no muestra ningún beneficio. Él escribió: «Probamos diferentes indicaciones de extracción, cientos de veces, para ver si el LLMS podría devolver información como el precio, los colores, los números de SKU. Sorpresa, sorpresa: esto solo funcionó en la página con información visible como texto».
Su prueba muestra que los LLM ni siquiera pueden ver el texto dentro de los datos estructurados.
Por supuesto, todo esto puede cambiar en el futuro, pero aquí hay algunas pruebas tempranas realizadas sobre esto.
Discusión del foro en LinkedIn.


