
En una publicación reciente de LinkedIn, Gary Illyes, analista de Google, destaca aspectos menos conocidos del archivo robots.txt cuando cumple 30 años.
El archivo robots.txt, un componente de indexación y rastreo web, ha sido un pilar de las prácticas de SEO desde sus inicios.
Ésta es una de las razones por las que sigue siendo útil.
Manejo sólido de errores
Illyes destacó la resistencia del archivo a los errores.
«robots.txt está prácticamente libre de errores» afirmó Illyes.
En su publicación, explicó que los analizadores de robots.txt están diseñados para ignorar la mayoría de los errores sin comprometer la funcionalidad.
Esto significa que el archivo seguirá funcionando incluso si accidentalmente incluye contenido no relacionado o directivas mal escritas.
Explicó que los analizadores normalmente reconocen y procesan directivas clave como user-agent, permitir y no permitir mientras pasan por alto contenido no reconocido.
Característica inesperada: comandos de línea
Illyes señaló la presencia de comentarios de línea en los archivos robots.txt, una característica que encontró desconcertante dada la naturaleza tolerante a errores del archivo.
Invitó a la comunidad SEO a especular sobre las razones detrás de esta inclusión.
Respuestas a la publicación de Illyes
La respuesta de la comunidad SEO a la publicación de Illyes proporciona contexto adicional sobre las implicaciones prácticas de la tolerancia a errores de robots.txt y el uso de comentarios de línea.
Andrew C., fundador de Optimisey, destacó la utilidad de los comentarios de línea para la comunicación interna y afirmó:
«Cuando trabajas en sitios web, puedes ver un comentario de línea como una nota del desarrollador sobre lo que quieren que haga esa línea ‘no permitir’ en el archivo».
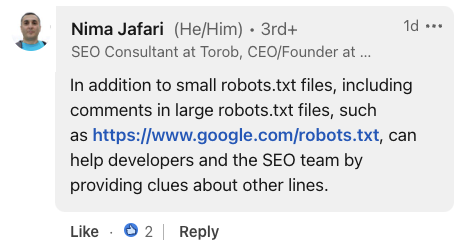
Nima Jafari, consultora de SEO, enfatizó el valor de los comentarios en implementaciones a gran escala.
Señaló que para archivos robots.txt extensos, los comentarios pueden «ayudar a los desarrolladores y al equipo de SEO al proporcionar pistas sobre otras líneas».
 Captura de pantalla de LinkedIn, julio de 2024.
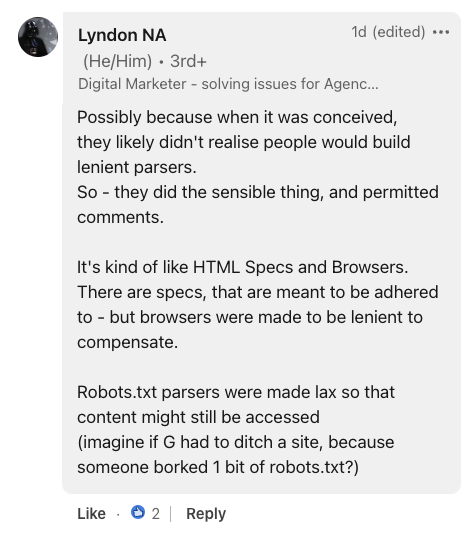
Captura de pantalla de LinkedIn, julio de 2024.Aportando un contexto histórico, Lyndon NA, un especialista en marketing digital, comparó robots.txt con especificaciones y navegadores HTML.
Sugirió que la tolerancia a errores del archivo probablemente fue una elección de diseño intencional, afirmando:
«Los analizadores de robots.txt se hicieron laxos para que aún se pudiera acceder al contenido (imagínese si G tuviera que abandonar un sitio, porque alguien borró 1 bit de robots.txt?)».
 Captura de pantalla de LinkedIn, julio de 2024.
Captura de pantalla de LinkedIn, julio de 2024.Por qué le importa a SEJ
Comprender los matices del archivo robots.txt puede ayudarle a optimizar mejor los sitios.
Si bien la naturaleza tolerante a errores del archivo es generalmente beneficiosa, podría provocar problemas que se pasen por alto si no se gestiona con cuidado.
Lea también: 8 problemas comunes de Robots.txt y cómo solucionarlos
Qué hacer con esta información
- Revisa tu archivo robots.txt: Asegúrese de que contenga solo las directivas necesarias y que esté libre de posibles errores o configuraciones incorrectas.
- Tenga cuidado con la ortografía: Si bien los analizadores pueden ignorar los errores ortográficos, esto podría dar lugar a comportamientos de rastreo no deseados.
- Aprovechar los comentarios de línea: Los comentarios se pueden utilizar para documentar su archivo robots.txt para referencia futura.
Imagen de portada: sutadismo/Shutterstock



